
Optical Circuit Switching 101: Better Than CPO?
Switch primer, OCS vs EPS, Spine Switch Replacement, Scale-Up OCS, TPU Superpod OCS, Types of OCS, OCS market modeling, Lumentum, Coherent, and a hidden smallcap OCS vendor

This is the OCS version of my very popular CPO 101 post.
CPO Supply Chain 101

The most important concept to understand when analyzing the CPO supply chain is the power of e x p o n e n t i a l.
A lot of people enjoyed it so I will be copying the format one for one because I am very uncreative.
Introduction
An OCS is just a mirror box. Light goes in, bounces off mirrors (or other stuff), then goes out in a separate direction.

The most important concept to understand when analyzing the OCS market is the power of a t t a c h r a t e.
The switch itself has a bunch of ports. Higher port count is referred to as higher radix.

Now the unit of measure for OCS shipments isn’t the number of boxes because boxes can vary in size. Big boxes cost more, small boxes cost less. Instead, it is the number of ports as the cost of a box generally scales with its port count.
Attach rate can therefore be defined as the rate at which ports are attached to XPUs. 2:1 means 2 OCS ports for every accelerator chip.
And for every OCS use case, the attach rate is rising.
On top of that, OCS itself is a new technology that is in the early-mid stage of its S-curve.
Therefore, this is an excellent market because its growth rate scales with three vectors: AI growth, adoption rate, and attach rate.
OCS growth rate = AI growth * adoption rate * attach rate
Contents
Switch Primer
OCS vs Electronic Packet Switch (EPS)
Spine Switch Replacement
Google TPU Superpod OCS
Scale-Up OCS
Types of OCS
OCS Market Model
Lumentum
Coherent
Hidden Small-Cap OCS Vendor
Final Thoughts: Better Than CPO?
SemiAnalysis Giveaway: The first person to subscribe using the paywall on this post will be selected to receive one free month of SemiAnalysis (sent to your email).
By accessing this content, you acknowledge and agree to our terms and conditions. This research is not financial advice.
Switch Primer
A switch is very simple.
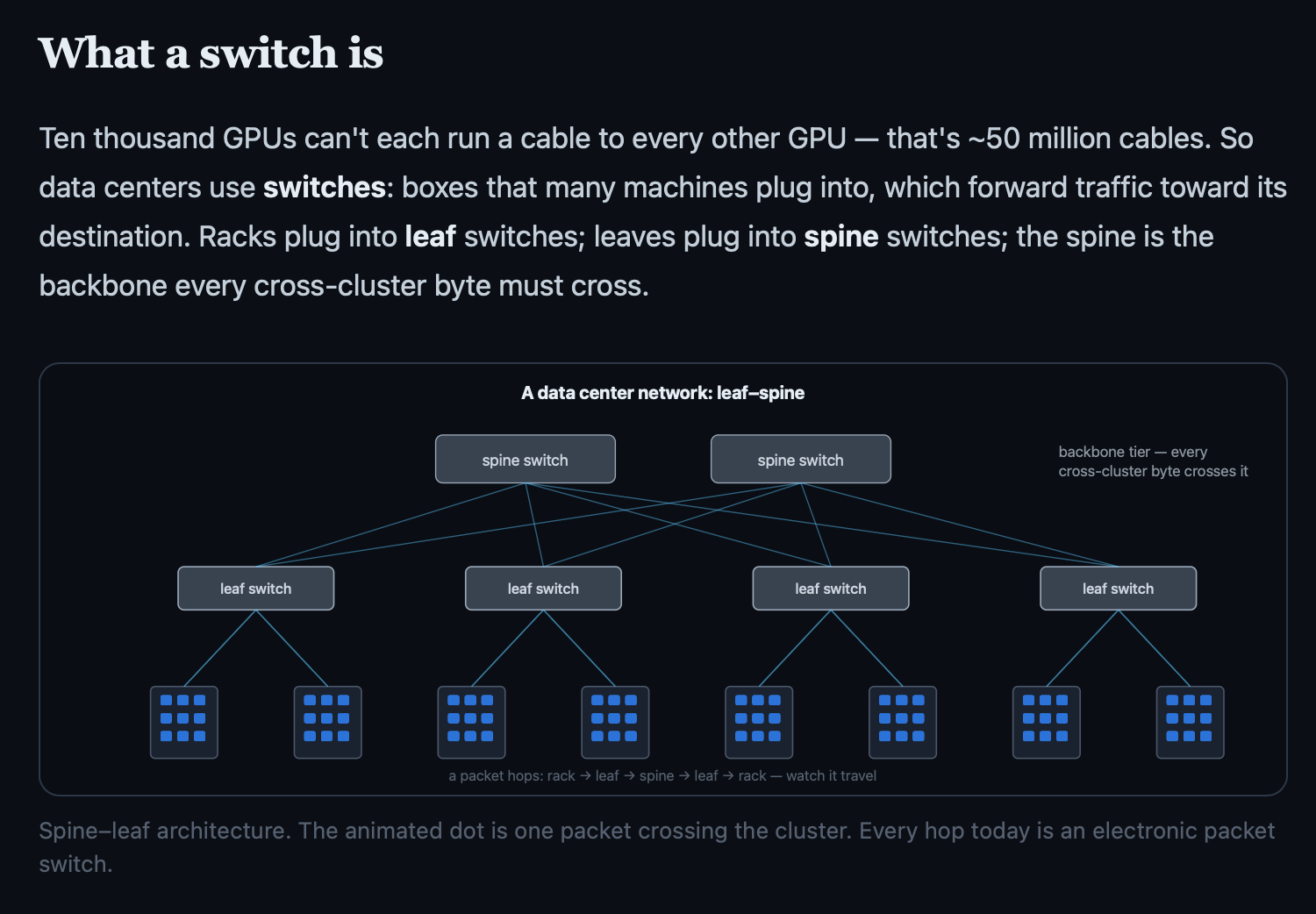
Data centers must be organized in a hierarchical pattern otherwise every GPU has to talk to every other GPU which means links scale at O(n^2) which would fill up the entire data center with wires pretty quickly which is generally considered to be not good.
In order to form this network, traffic must be routed, and it is switches that route the traffic.
OCS vs Electronic Packet Switch (EPS)
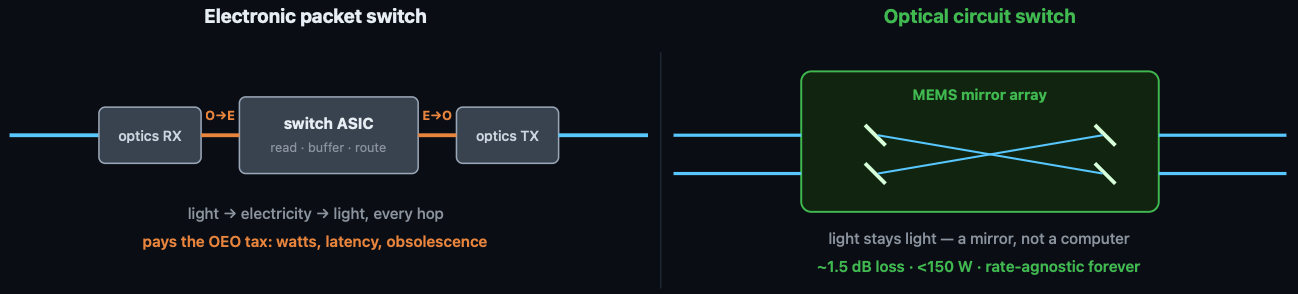
An Earnings Per Share (EPS) (lol) is the standard electrical switch that is currently used almost everywhere.
It receives an optical signal as an input via transceiver, converts it to an electrical signal, reads and routes that signal via switch ASIC (logic chip), converts it back to an optical signal via transceiver, and sends it to its destination.
An OCS, on the other hand, just bounces the light off of a mirror.
So think about intuitively what the trade-offs are.
If you have to convert a signal from optical to electrical and back to optical (OEO), that certainly takes time. It also takes energy. The switch itself is also active, which takes even more energy. So generally the big problems with an EPS are latency and power.
It’s not like this is a small difference btw. OCS is practically free compared to an EPS. Lumentum on their R300 switch:
The R300 has demonstrated 98% reduction in switch latency vs. an OEO packet switch solution.
The power requirements of OCS is also less than 10% of an EPS.
But obviously an EPS is better in certain ways. Otherwise, why is it the most widely used solution?
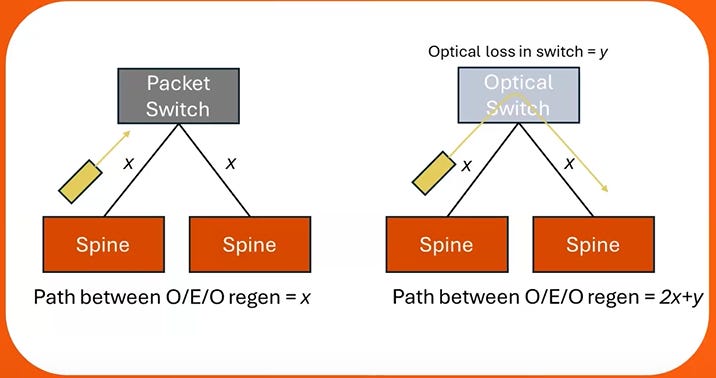
Think about what happens when the signal exits the switch system via transceiver. It gets received, then re-sent, meaning that the signal coming out the other side is a fresh beam of light. On the other hand, in OCS, the light bounces off the mirror and loses a bit of signal and isn’t re-amplified again.
In addition, intuitively speaking, the light also has to travel twice the distance because it never gets to stop at the switch. Think of it like taking a direct flight instead of a layover.
As a result the signal suffers more insertion loss which means that when the signal finally arrives at its end destination it is a lot more mangled. Specifically, if the insertion loss from distance (in EPS setup) is x and the switching loss is y, the total OCS insertion loss is 2x + y.
The other tradeoff is that moving mirrors to redirect connections takes time. Not that much time, only milliseconds. But EPS can make fresh routing decisions for every single packet. This is the problem behind the core reason OCS was not a thing before AI, which I will lay out for you now:
Traditional cloud traffic is mouse flows.

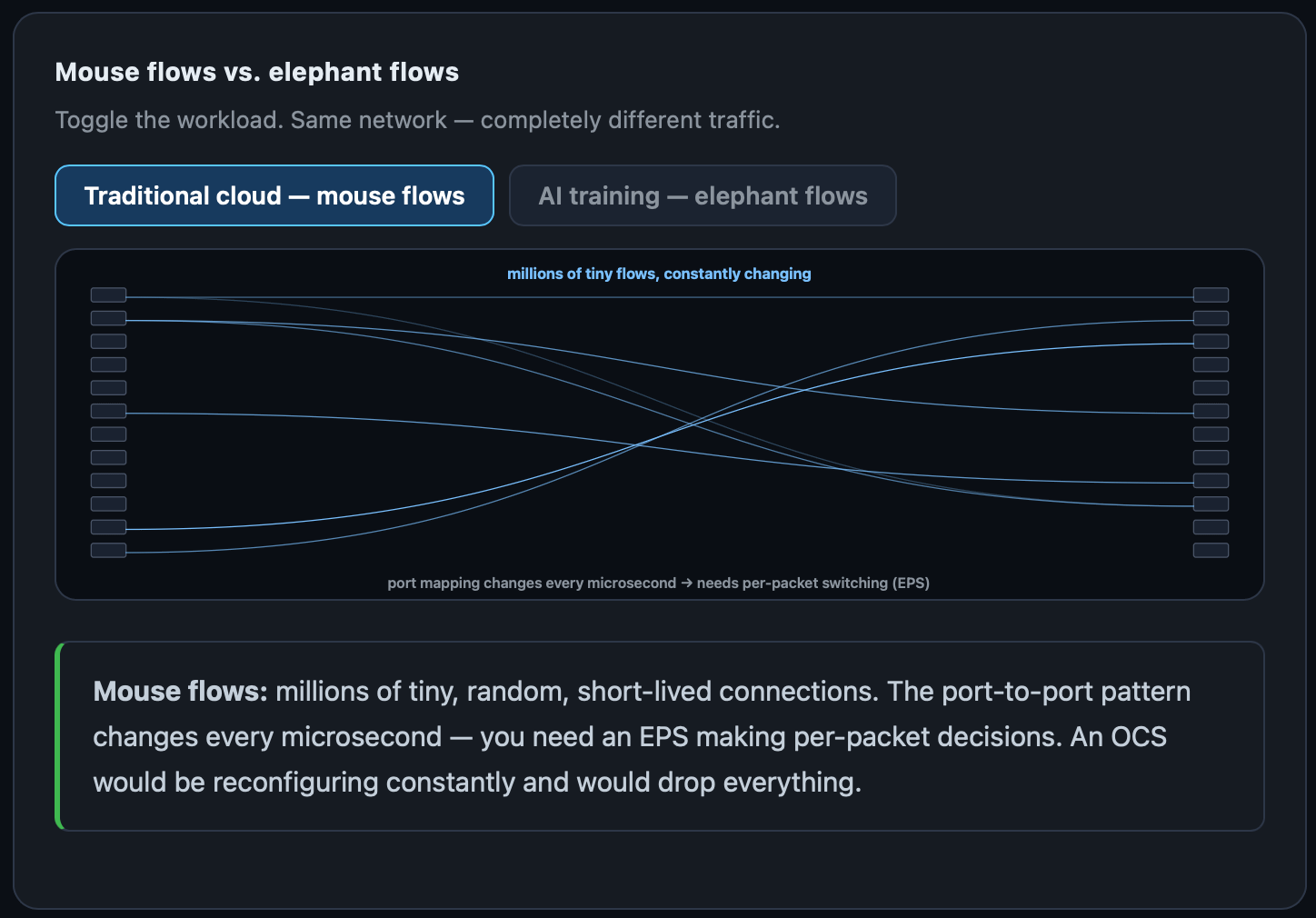
These are tiny, short-lived, and unpredictable connections (a search query and API call, a checkout). You need a switch to actually make decisions for every packet. The connections change too fast for those micro mirrors to handle.
AI workloads are elephant flows.

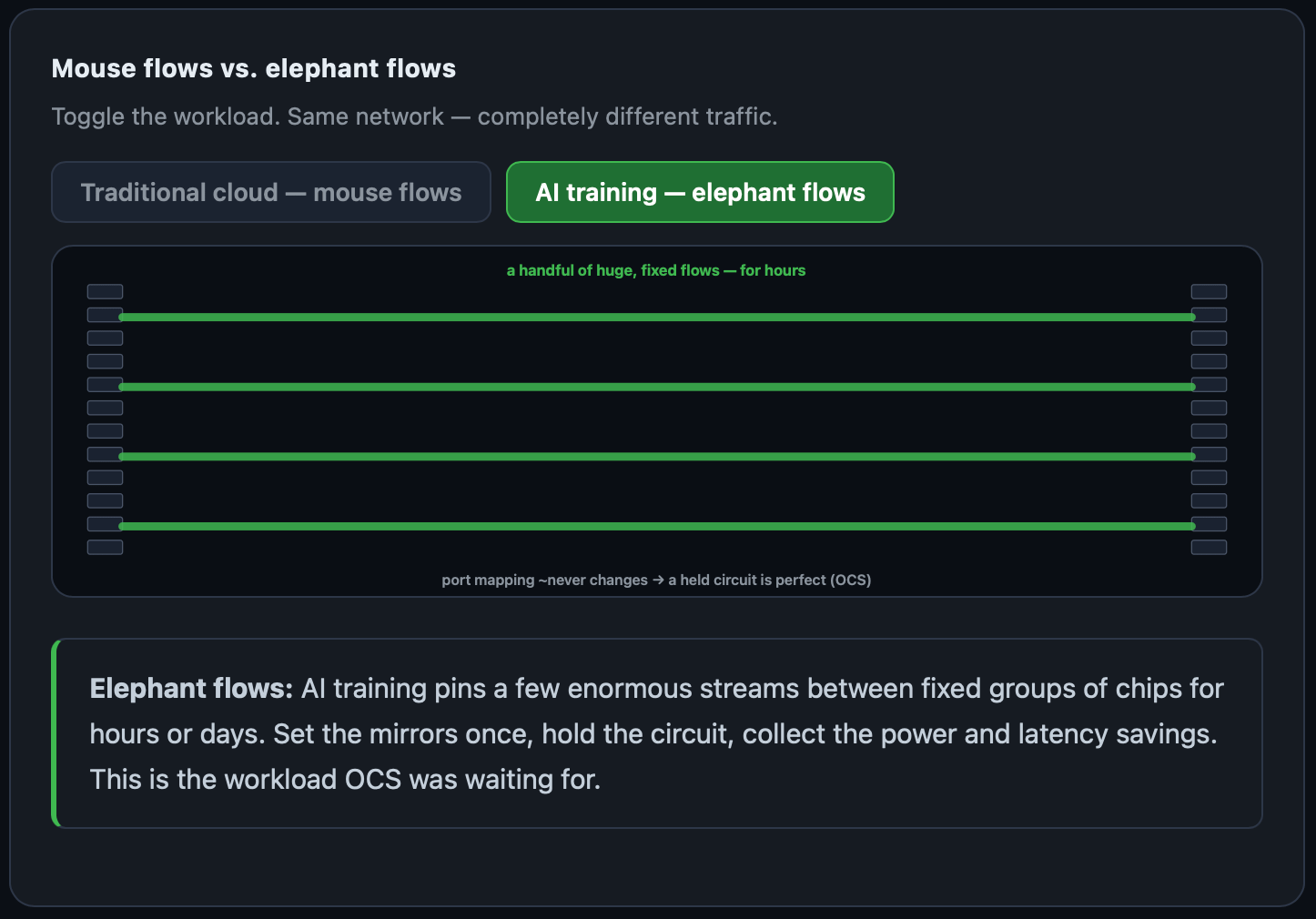
Training points the same exact clusters of accelerators to each other and leaves the connections alone for hours.
OCS bears would say that as we move to inference, we move back from elephant flows to mouse flows, as each individual user query is distinct. This may be true at the leaf level. However, at the spine level (where OCS sits), the network traffic is still classified as elephant flows, as the only data that passes is prefill to decode KV transfer and not the individual tokens.
Spine Switch Replacement
Now, let’s talk mirror box use cases. There are three of note that we will discuss today:
Spine switch replacement
Google TPU Superpod OCS
Scale-up OCS
Spine switch replacement refers to the replacement of the spine switch.
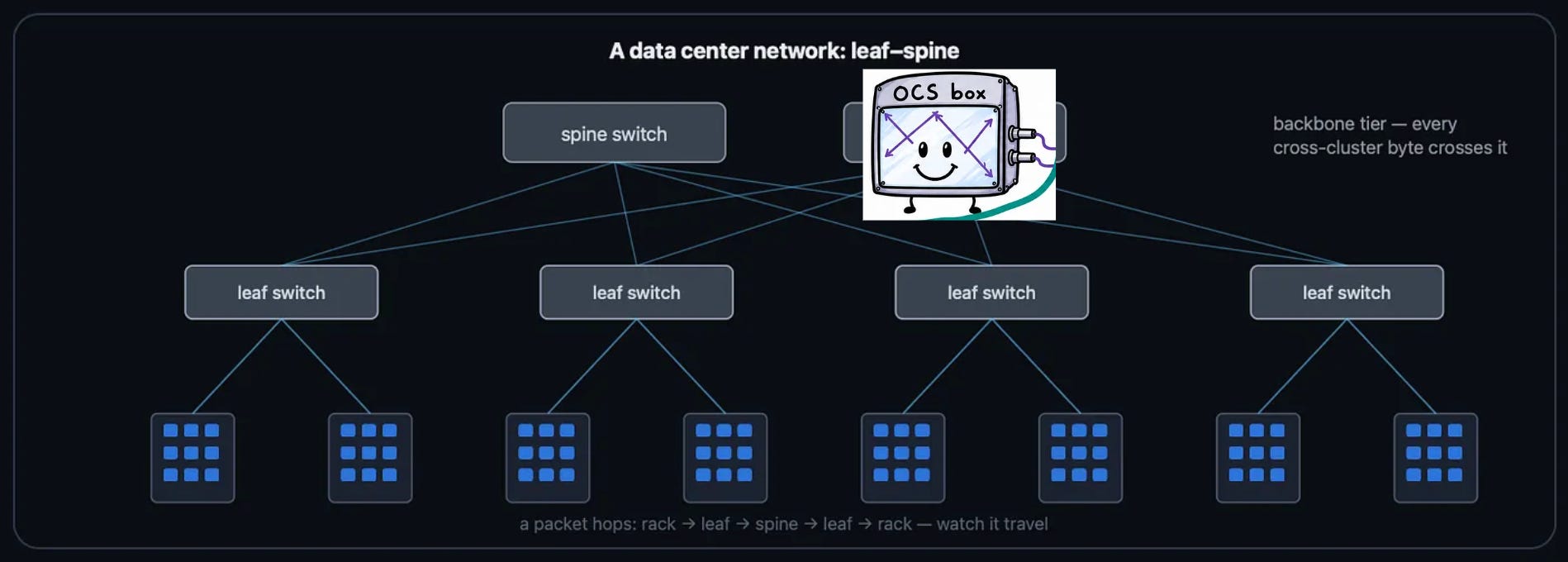
This is the perfect (and generally the canonical) use case for OCS. At the spine switch level, almost all AI workloads are elephant flows. Spine OCS is nearly free compared to a spine EPS, so free in fact that it lowers the spine capex by 30% and power consumption by 40%.
The thesis is simple: current spine OCS penetration outside of Google is under 5%. That number is gonna increase. Each EPS that gets replaced with an OCS adds to the yearly CAGR. This is an adoption rate story.
However, we still have to get around this insertion loss issue. The current link budget of 4 dB can barely take one OCS hop.

So what’s actually going to spark the adoption?
Coherent-Lite Transceivers!
Optical communication is simply transmitting data through light. There are two ways to encode data in light (known as modulation): IMDD and coherent (no not the company).
IMDD is basically flashing a flashlight on and off. Only encoding signals in brightness.
Coherent modulation is like having one of these:

It encodes signals in brightness, phase, and amplitude.
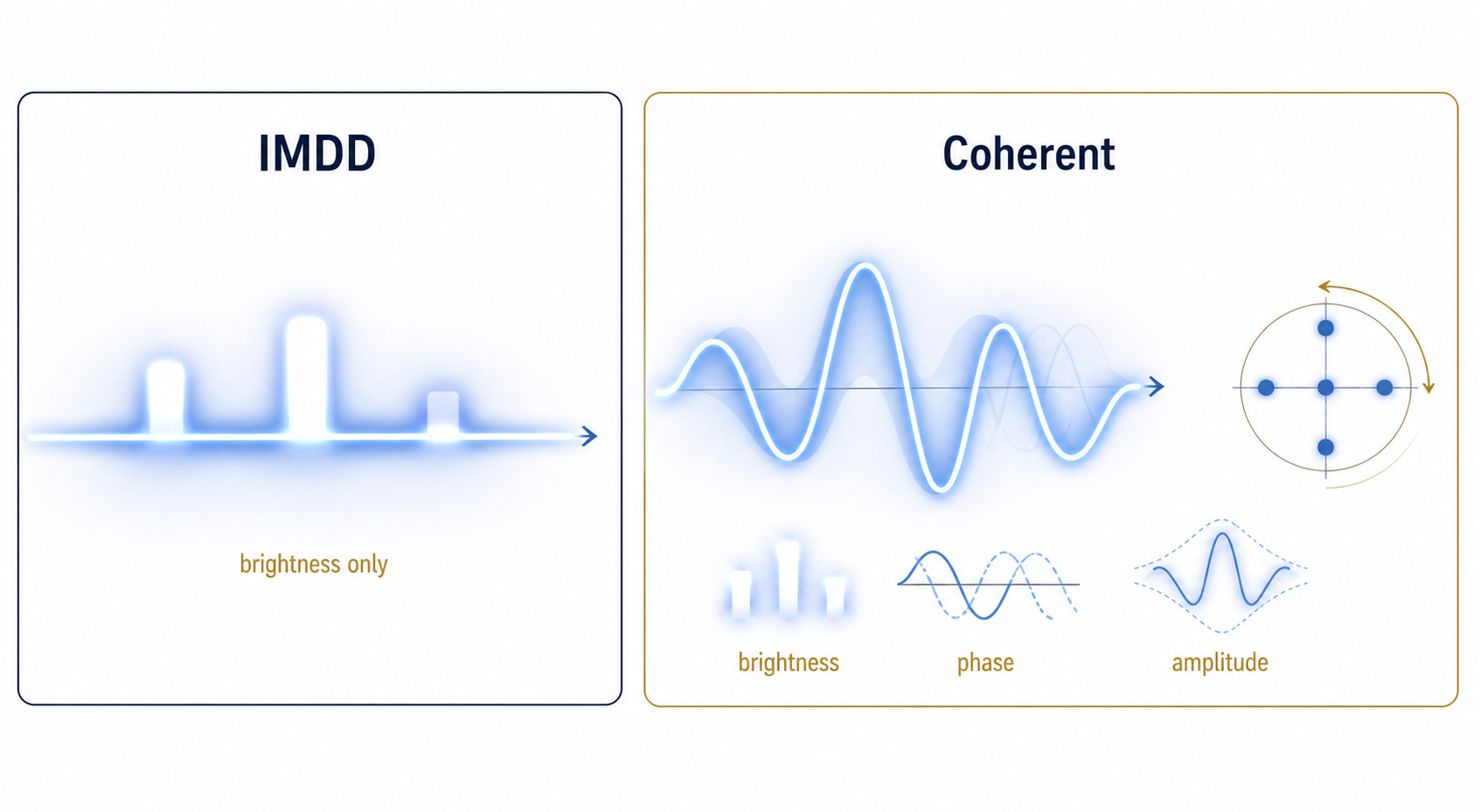
The benefit of coherent modulation is that it makes it much easier for the receiver to detect the signal, therefore allowing the it to survive a greater insertion loss (higher link budget). This is why coherent is used for long-reach telecom and scale across.
On the other hand, it is much more expensive and complicated, as you can imagine.
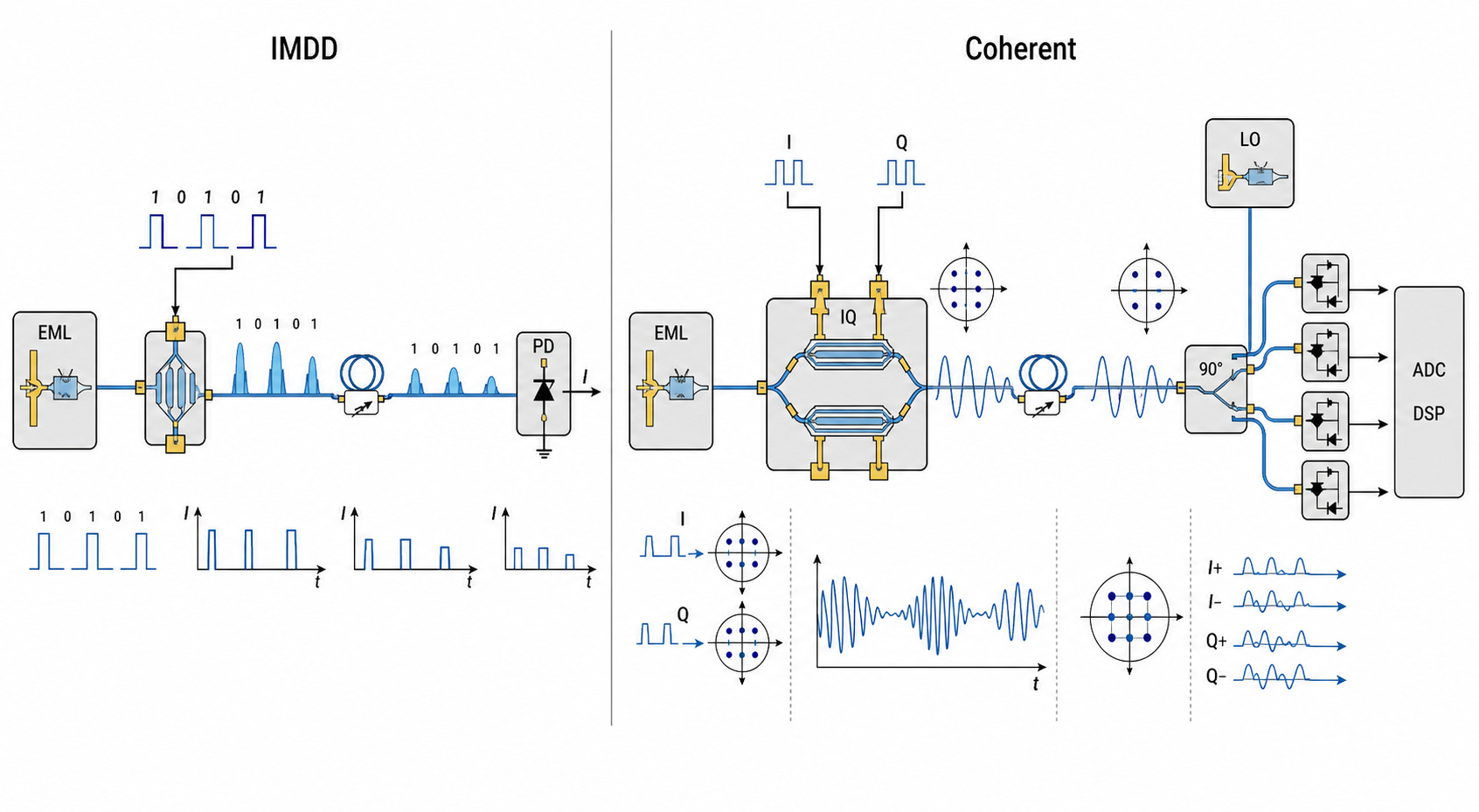
Therefore, scale-out is moving to adopt a light version of Coherent known as Coherent-Lite (Yes i know it sounds like a Coherent and Lumentum merger. Who named these modulation schemes?).
As these transceivers get adopted, the link budget doubles or triples, allowing for plenty of room for OCS hops. In fact, we will have so much link room that the light can handle two hops at once. Meaning it’s possible to build networks with a spine and super spine architecture, both of which are OCS.
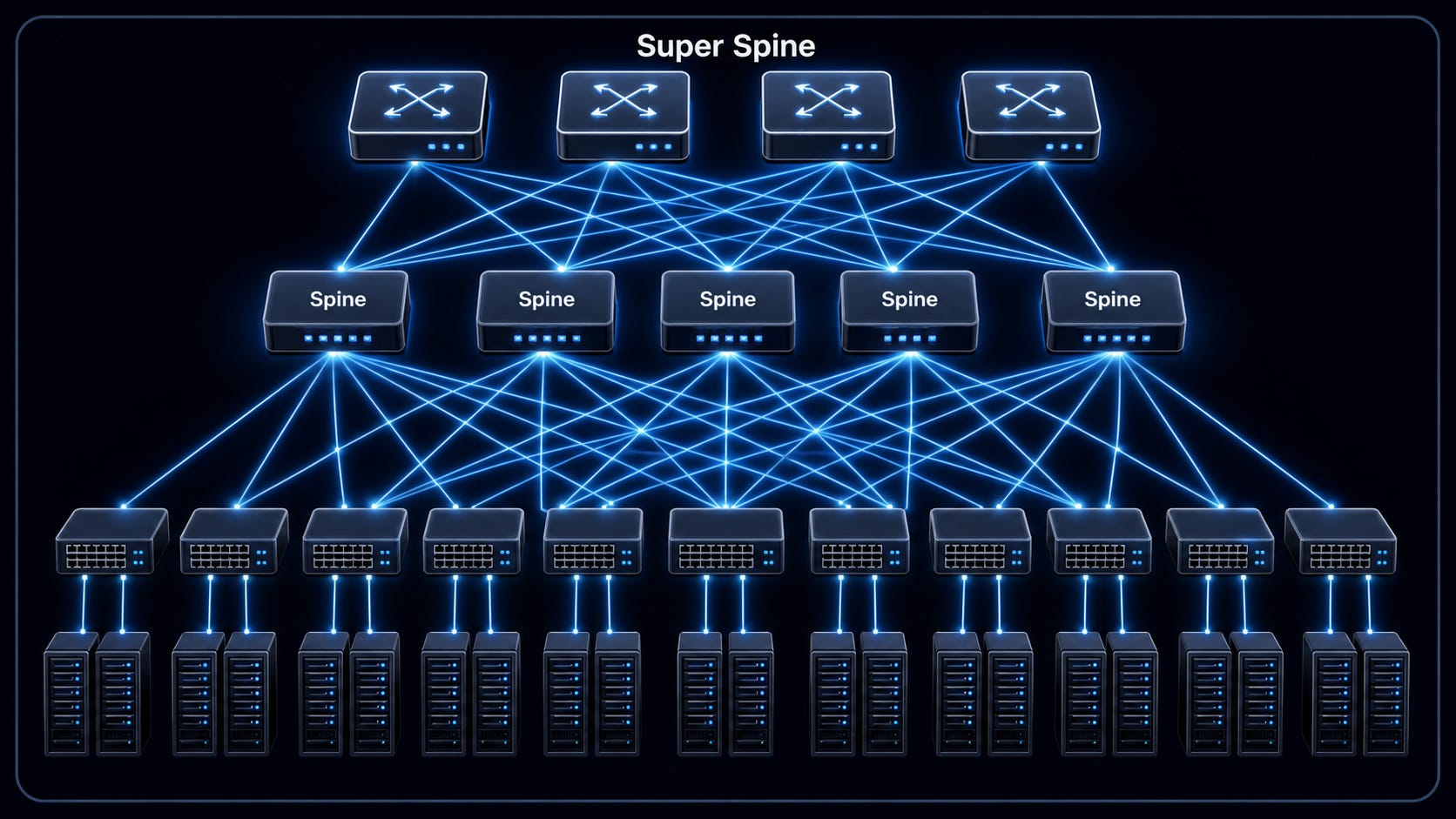
Google TPU Superpod OCS
Google’s architecture is weird.
Nvidia (NVL72) is very simple and intuitive and easy to understand. Each rack of 72 GPUs is its own scale-up domain (one compute and memory “unit”). The scale-out fabric connects these racks together via transceivers, leaf switches, and spine switches.
Google’s interchip interconnect (ICI) is its scale-up network, but unlike NVL72, it isn’t one rack. Instead, it is a hodgepodge of 9,216 TPUs which share one gigantic memory domain but are connected with “racks” that are each a 4x4x4 cube of 64 TPUs (copper inside the cube, transceivers connecting cubes to each other). That’s why it’s called a superpod.

The pod is shaped like a 3D torus, so basically a giant chip donut.

Each one of these super pods has 48 OCS. Therefore, there is a deterministic port-to-TPU ratio of 1.5:1. So in essence, OCS scales with TPU shipments.
But it gets better. There’s an attach rate story too.
This is based on the excellent work by FundaAI.

A 3D torus is built for an all-reduced communication pattern, which is common in training. Each chip mostly talks to its nearest neighbors, and results ripple through the network like a class of middle schoolers passing notes to each other until everyone reads it.
However, in inference for mixture-of-experts (MoE) models, the communication pattern changes to all-to-all. Every token gets dispatched to separate experts living on chips scattered anywhere in the pod.
Instead of middle schoolers passing notes to each other, it’s like every kid has to talk to every other kid at the same time. But for our purposes, let’s now use a better analogy. Think of the data center doing an all-to-all communication like a city. Every household drives to the far side of the city at once.
Now let’s try to make the problem clear. Imagine in this city there is a central intersection. When there are thousands of cars trying to cross to the other side, there may or may not be mild traffic.

In the data center, this is known as the bisection bandwidth, which becomes a critical spec when all-to-all communication is necessary.
Eventually, this problem needs to be fixed. You’ve thought of every possible solution, but nothing seems to get over the fact that in a two-dimensional plane, there’s only so much space for roads, and you just can’t fit all the cars.
So you hire a genius city planner. By virtue of having infinite tax revenue, this person decides to give everyone a helicopter. Now, there’s not a central intersection. Instead, there’s a central airspace, but because you’ve added a dimension, the bisection bandwidth is no longer a constraint at all.

Bisection bandwidth for N chips given n dimensions scales with the following equation:
bisection bandwidth ∝ N(n−1)/n
so
N2/3 in 3D → N5/6 in 6D → N1 as n→∞
This is essentially what Google is thinking of doing: moving from a 3D torus to 4D or higher. And each time you increase the dimensionality, the OCS ports per TPU mathematically increase.
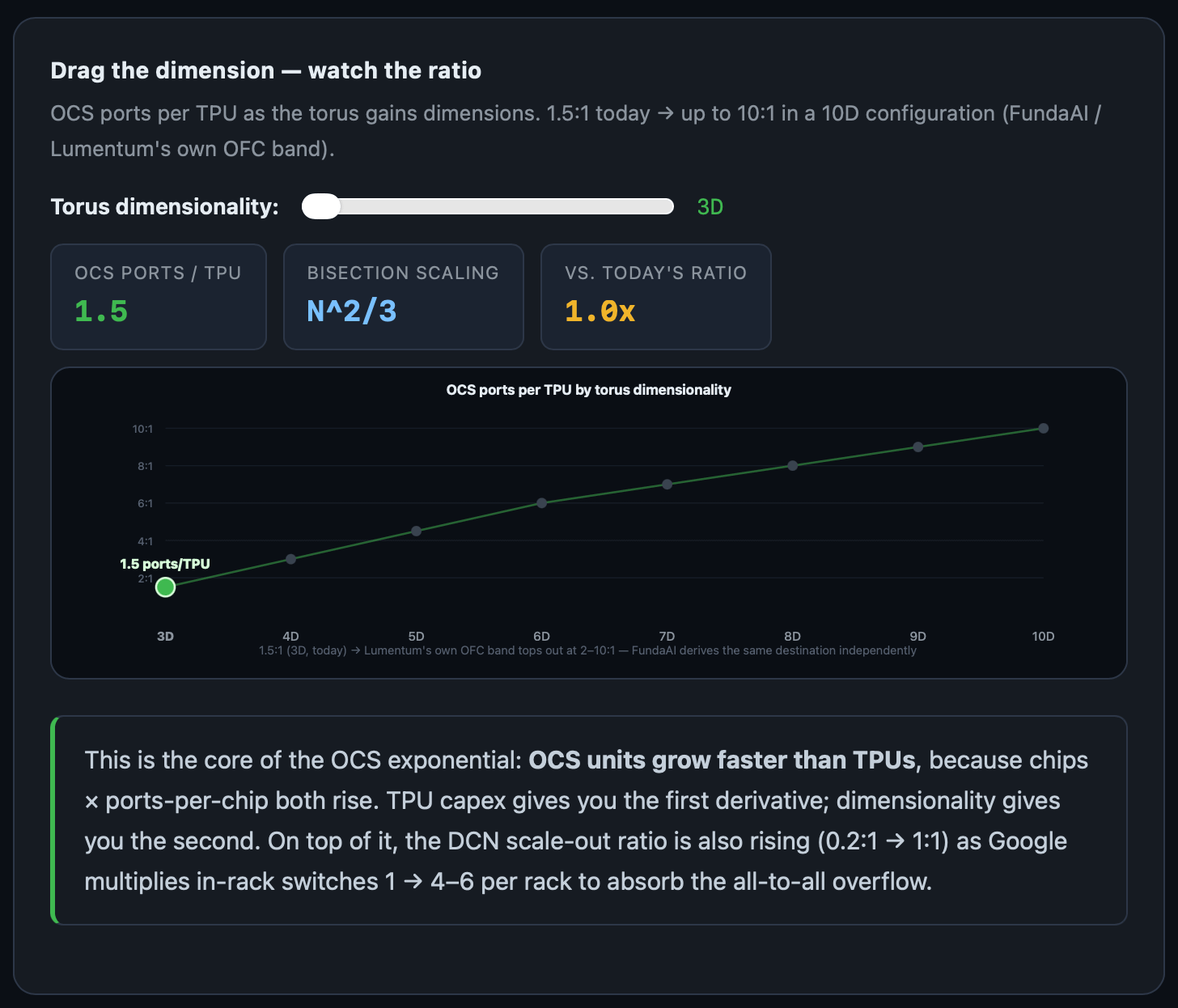
This will take a while. It’s not like it’s going to happen in 2027. The patents for a 4D torus are filed, but in TPU v8, Google is sticking with a 3D torus. This is likely something on the same timeline as scale-up TPU, like 2029 to 2030 or later. But it has the potential to double the attach rate in the medium term (3:1 in a 4D torus) and in the very long term, a ceiling of 5x or more (to 10:1 ratio).
Scale-Up OCS
Optical scale-up, the act of connecting the GPUs inside of a rack with fiber instead of copper, is the crown jewel of the CPO market, but for OCS, it is only an interesting call option.
This is because, unlike CPO, scale-up OCS is completely optional!
The idea is to place OCS directly into a rack to replace NVlink switches, but the thing is there’s no law of physics forcing the regular switches to fail in the optical scale-up world. It’s merely a choice by the vendor for what kind of switch they want to use. This is why I won’t be focusing on this market or modeling it very intently.
Types of OCS
As we discussed, the two main drawbacks of optical mirror boxes are the speed of redirecting connections and the insertion loss. These two drawbacks also serve as the main trade-offs between the different types of OCS. We will discuss liquid-crystal and MEMS in this section because they are the two relevant types of OCS for today’s data center deployments. Piezoelectric and Sipho will be saved for later — you will see why.
The simplest way to think about the difference between MEMS and liquid-crystal is that for MEMS you reflect light off of stuff (mirror), and for liquid-crystal you steer light through stuff (medium). All of the spec differences stem from this.

Here is a tier list of the relevant mirror box specs.
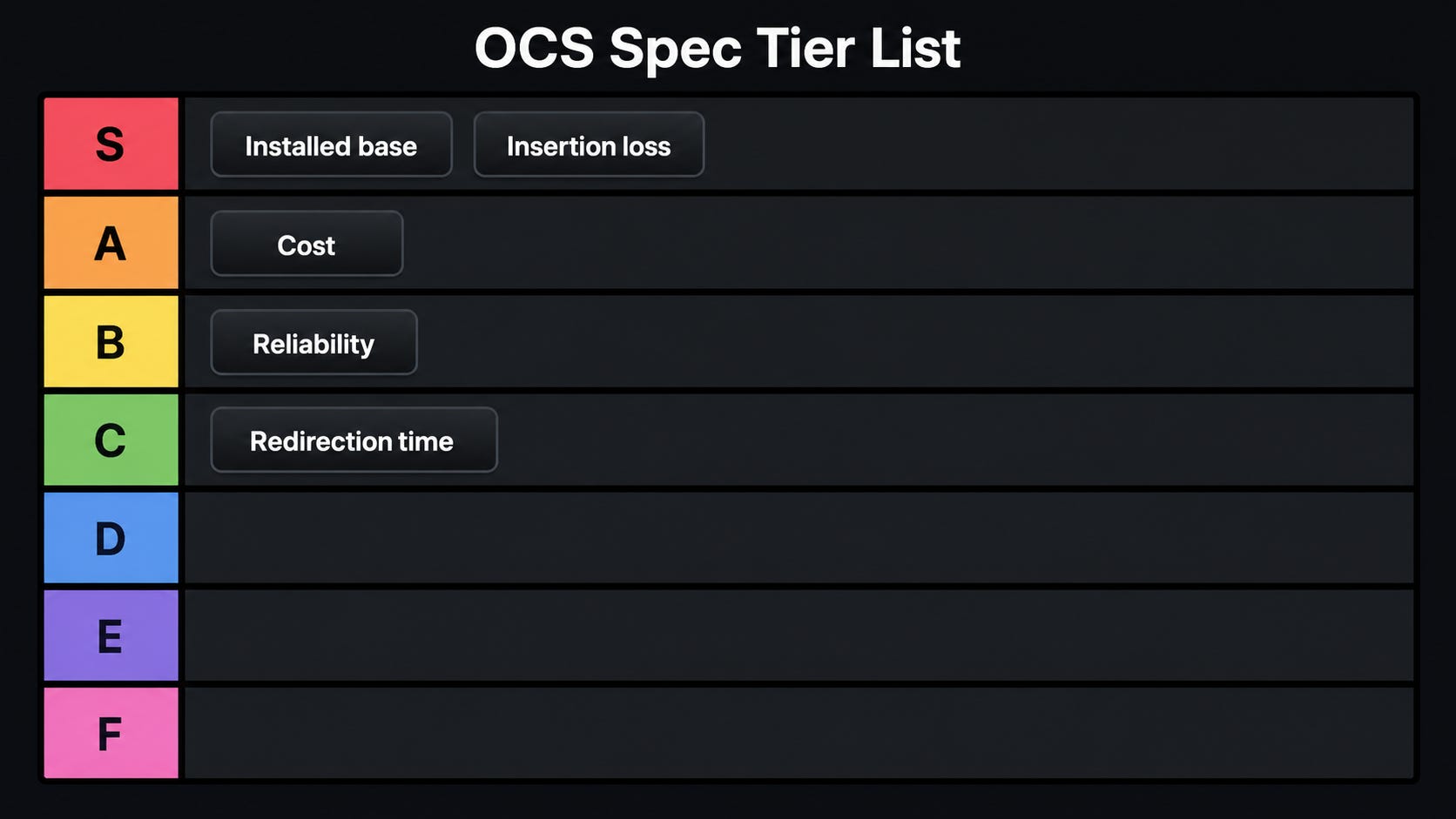
Let’s start with insertion loss and cost.

Liquid-crystal and MEMS are very similar cost-wise, but MEMS decisively wins in insertion loss. This is probably the biggest and most important difference between the two types of OCS. MEMS has a 1.5 dB insertion loss versus 3 dB for LC. Decibels are measured on a logarithmic scale too, with 10 dB being one order of magnitude, so 3 dB means that you lose half your signal in one hop. It’s pretty bad.
From Lumentum’s OCS webinar in 2025:
This capability is embodied in the R300, which currently supports up to 300x300 ports with a typical insertion loss of 1.5 dB or less. And a note about the importance of low-loss performance –this is a critical feature, as it is one of the key technical hurdles to the introduction of OCS technology into hyperscale environments. This is seen in the requirement to support additional OCS loss within transceiver link budgets – around 4dB for FR4/DR4 and 6dB for LR4/ER4.
The core mechanism behind this difference is that, for a liquid crystal, you must first split the light, then have it pass through an active medium where some light is absorbed, and then recombine it. Both the splitting and the passing-through-a-medium create insertion loss.
Meanwhile, MEMS is literally a mirror. A literal mirror.
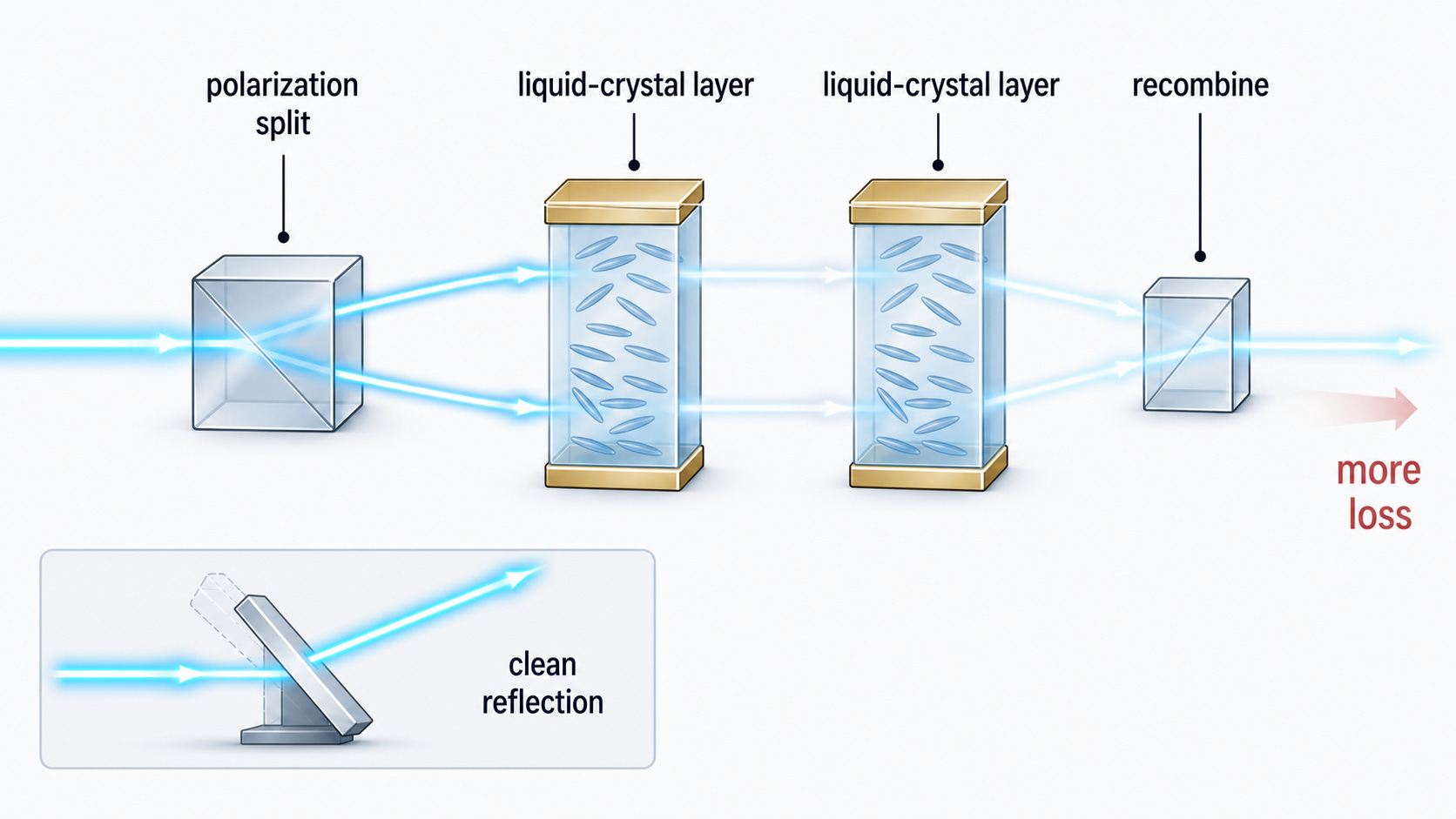
Liquid crystal makes big claims about their reliability versus MEMS, some of which I think are a bit overstated. For example, there is one claim that MEMS wears out after three years because of its moving parts. This fundamentally overlooks the fact that even though the parts move, they don’t slide against each other, and there is, in fact, no friction. Moving parts doesn’t mean sliding parts that wear out.
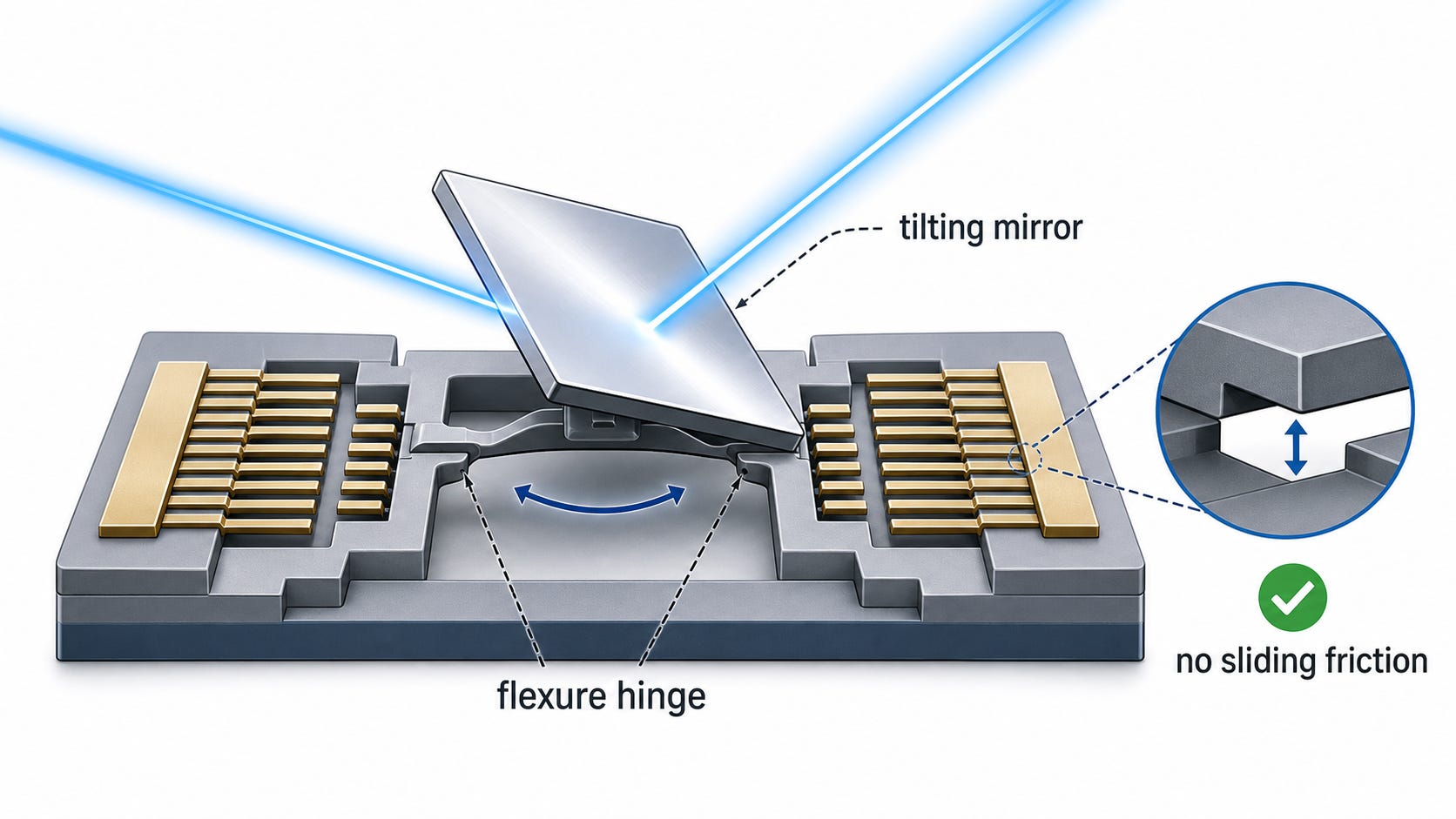
Google’s MEMS fleet has been in production for a decade with tens of thousands of units. If MEMS switches failed after three years, they would probably notice and say something about it.
However, the reliability of liquid crystal is still much better.

This is due to the system having no moving parts (mirrors) and operating with much lower voltage components.

Now let’s discuss redirection time. This is what dictates how long it takes for the switch to change your port connections.
Currently, MEMS and liquid crystal are about tied at a range of 10-100 ms (liquid crystal slightly slower actually).
However, a new type of liquid crystal in development, ferroelectric LC, switches in 10-100 microseconds instead. This is a a next-generation material for Coherent. As a result, switching time is decisively won by liquid crystal.
But there’s a reason why I put redirection time in C tier.

If you even decide to use OCS, you only have to change port connections when you reconfigure your network. This happens on an order of minutes to days. Microseconds or milliseconds simply do not matter.
Finally, let’s discuss install base.
MEMS wins here for a very simple reason: Google.
Google is by far the largest employer of OCS in the world and has had a fleet of them operating for a decade. They are actually the pioneers of their technology, producing most of their switches in-house (under Palomar brand) before the massive wave of AI demand forced them to externalize. And it’s all MEMS.

Read their Mission Apollo paper if you’re interested in learning about their deployments. But notice how MEMS-centric it is.

This is S tier. This matters a lot. Proven reliability at scale is a defining requirement for data center procurement officers.

Overall, MEMS is way better.
But this doesn’t mean that liquid crystal won’t get any adoption. It is still viable technology and the specs here don’t decide adoption as a binary. If MEMS vendors’ capacity is sold out, hyperscalers will happily buy liquid crystal. Having an OCS at all is what matters more.
Below, I will share my detailed model for the OCS market with accelerator shipments, TPU shipments, external merchant share, ASP, and port ratios informed by industry checks. I will discuss Lumentum and Coherent as players in this market and how I expect it to be split between the two of them, with models for each. Finally, I will share a hidden small-cap OCS vendor.