
Cerebranalysis | Part 2: The Perils of Real World Inference
Turning experience testing the only custom designed model for Cerebras (GPT 5.3 Codex Spark) into an investment conclusion

Welcome (back) to Cerebranalysis (part 2)!
Yesterday, we covered Cerebras’ technology (dinner plate computing), which is a prerequisite to this article as we build upon the main conclusion from that piece.

Today, we will be going over the financial and business side of things and actually analyze Cerebras as an investment. This will include extensive testing of an actual model running on their hardware for real-world agentic inference tasks. Exciting right?

By accessing this content, you acknowledge and agree to our terms and conditions. This research is not financial advice.
Financials
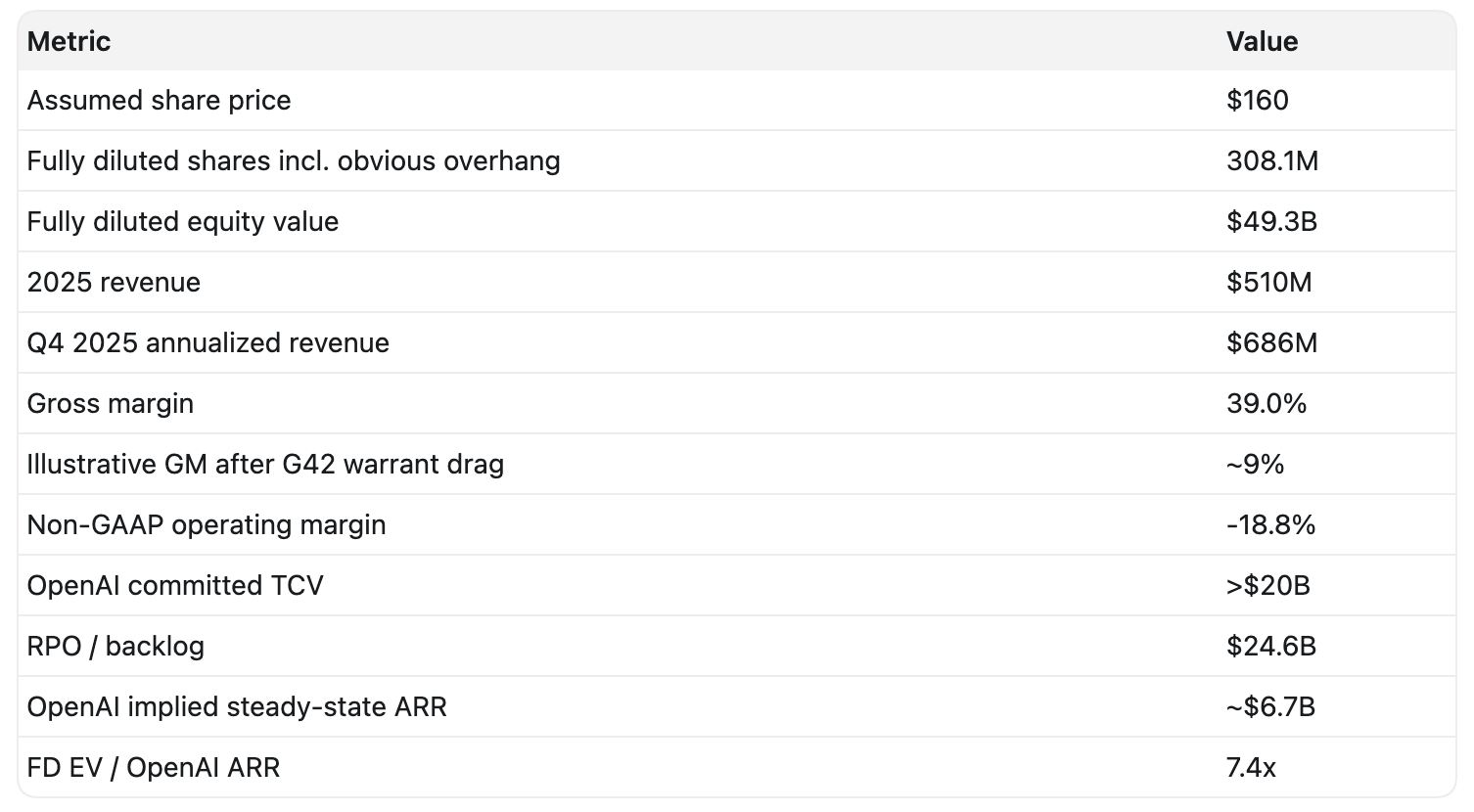
Cerebras IPO was 20 times oversubscribed at the initial $130 share price. People really want to buy this thing. Yesterday, they raised the IPO price to $160. Polymarket still has almost a 100% chance that they will close above a $50 billion market cap (that is for their basic equity value, which is only around 70% of their fully diluted, so it is way higher than what’s shown in the table).
Their 2025 revenue is miniscule and irrelevant at $510m. Currently, they have $24.6b RPO and $20b of contract value from OpenAI, which can be expanded over time, but this implies a $6.7 billion steady-state ARR.
At the assumed IPO price of $160 per share multiplied by the fully diluted share account, the implied revenue multiple to OpenAI’s ARR is 7.4x.
The First Noble Truth of Cerebras
The following is the first Noble Truth of Cerebras.
The financials are useless. Completely utterly useless. Forward estimates are useless. Growth rates are useless. Multiples are useless.
Now, why is that? Let’s think about this from first principles.
How To Think About Cerebras
Cerebras is a canonical example of an unproven technology early in its S-curve with potential for high double-digit to triple-digit growth. This high-level conceptual profile allows us to anchor to two companies that have plenty of coverage on this channel: Lumentum and Bloom Energy.
Lumentum
The 30,000ft intellectual framing of Lumentum is simple: one market (optics) is guaranteed (by the laws of physics) to replace another (copper) to achieve full dominance of a certain use case (AI networking).

Because the transition is inevitable, the leading players in the new market have a massive guaranteed growth runway. This is why optics are so hot.
At the same time, the growth is measured and measurable. It is easy to model. We can confidently predict that Lumentum has 50% year-over-year growth because we can simply use the growth rate of optics as an anchor.
Bloom Energy
Bloom is slightly different. One company provides an objectively superior solution for one single market, which has the potential to fully displace the incumbent.
This is different from Lumentum because the market doesn’t change. Bloom plays in behind-the-meter energy, just like GE Vernova. They are direct competitors. There is no copper equivalent. There is no transition from one market to another.
Because of that, Bloom’s growth can be a little bit more unpredictable and bursty. There is no big Kager number to go off of. It is just a matter of how quickly customers adopt the new solution and how much, or if, the new solution is superior to the old one. However, growth here is still predictable. If the new solution is better, it will still slowly displace the incumbent.
Cerebras
Cerebras is completely different.
From our first article, we ended with the ultimate conclusion that Cerebras is a provider of a fundamentally different product than Nvidia: premium tokens. Premium tokens are way faster but cost way more.
Is Cerebras like Lumentum? No, there is no world in which premium tokens will inevitably displace normal tokens. They are simply two different products each with a different trade-off.
Is Cerebras like Bloom Energy? No. WSE is not a superior way to generate the same end product (electricity for Bloom, regular tokens for NVIDIA).
In both comparisons, Cerebras is actually much worse. It’s not guaranteed to take share from anyone, really. However, there is one critical distinction, and it’s very critical. Very, very critical.
The inference market is the single biggest market in the world.
AI networking and behind-the-meter power are big markets, but they’re not the biggest. Inference is, and the current incumbent is the biggest company in the world. If these premium tokens carve out a large enough slice of this overall pie, Cerebras is a very attractive investment. The only question is, will it carve up a larger left slice? Again, unlike Lumentum, it is not guaranteed to take any share at all.
Now you probably understand why I say that the financials are useless. Single-digit billions of ARR do not matter at all. If you are unprofitable and your market is the biggest market in the world, what matters much more, and really what matters at all, is the slice of the fast inference pie.
No amount of revenue will save Cerebras from offering a fundamentally unwanted solution. No valuation is too high if they serve a sizable fraction of all inference.
Therefore, the point of this article is to simply assess how likely it is the fast inference market ends up being incredibly large.
Abstract
To assess how likely it is that the fast inference market ends up being large, we must observe and test how performant and useful fast inference is today.
There is significant alpha in the testing. Just by observing the everyday experience of using the model, we can literally feel the components that bottleneck inference (hint one of the market’s current favorite themes) and reason about whether Cerebras is positioned to solve it.
For my testing, I completely disregard classic benchmarks that are unrepresentative of actual work and instead focus on two real-world tasks that I perform every day: equity research and coding. For equity research, we ask the model a classic retrieval question, and for coding, we have it develop a feature in a (real!!) live application and compare them side by side.
Through these two tests we observe what actually bottlenecks inference speed on a day-to-day basis and link this to our silicon world. We evaluate 5.3 codex Spark on both its real vs claimed speedup and the performance relative to the frontier.
We synthesized the results from our tests into a conclusion about the speed and the performance quality of 5.3 Codex Spark and Cerebras hardware.
Then I underline three potential bull cases:
The undiscovered TAM, where nobody knows what fast inference could be used for, so we are underpricing it today. I describe three potential market fits:
Fast fundamental investing
Embodied and human-like AI
Real-time human augmentation
The low-hanging fruit: architectural innovations that Cerebras can easily make, which would be a step function change in their unit economics. These include FP8/FP4 support and hybrid bonding.
Why they are the only choice for the non-NVIDIA ecosystem.
Most importantly, I culminate both yesterday’s and today’s research into a final conclusion and what I personally am doing at IPO.
Contents
5.3 Codex Spark
X Sentiment
My Own Testing: Equity Research
My Own Testing: Coding
Conclusion
Bull Case
The Undiscovered TAM
The Low Hanging Fruit
The Non-Nvidia Ecosystem
Conclusion and What I’m Doing at IPO
5.3 Codex Spark
5.3 Codex Spark is the custom-developed model by OpenAI, specifically made for running fast inference on Cerebras hardware. It is currently the only custom design model for Cerebras hardware, so in reality this model is one of, if not THE most important element of any Cerebras investment analysis. But for some reason, it is very under discussed.
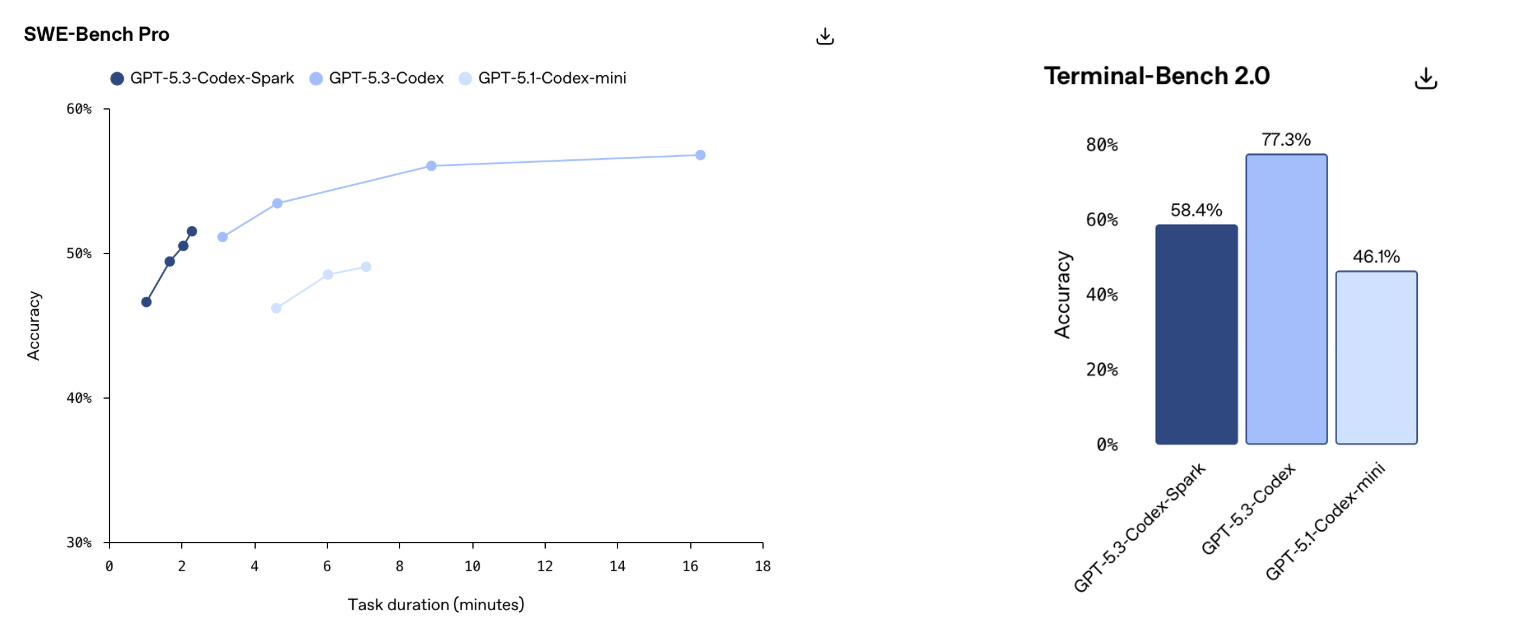
It trades a large chunk of its performance to be smol. It features substantially lower benchmark performance, a context window that is one-eighth of the leading frontier models today, but with inference speeds of over 1,000 tokens per second.
As we established in the last post, in order to run a model of a certain size, a certain number of dinner plates must be strung together. The larger the model weights, the more wafer-scale engines are needed, and the more uneconomical it becomes. Therefore, small models are much more cost-efficient for Cerebras to run.
Now, how good is this model exactly? Here is where I found something funny.