
The Lumentum Series | Part 2: Co-Packaged Omnipotence
The full CPO thesis for Lumentum. Revenue builds for CPO segment and EML/CW lasers.

Opinions are my own and do not represent past, present, and/or future employers. All content is based on public information and independent research. This newsletter is not financial advice, and readers should always do their own research before investing in any security. I am invested in the semiconductor industry. As of the date of this publication, I currently hold a long position in Lumentum Holdings (LITE). Exaggerations or memes are for entertainment, humor, and funny purposes only and do not constitute predictions. Feel free to reach out at jasonschips@gmail.com.
I love how if you go to Lumentum’s website, they lay out their products like it’s an ecommerce store and I can actually order my External Laser Source (ELS) Module with Ultra-High-Power Laser.
That ELS product is the topic of our discussion today, and it is one of the two true drivers of Lumentum’s 300% rally over the past year. Today, I’ll take you on a journey to understand why CPO is inevitable. Which means ELS is inevitable. Which means ultra high power lasers are inevitable. Which means:

We’ll then review the competitive landscape to see why I believe, in the Co-Packaged Optics market, Lumentum has achieved… Co-Packaged Omnipotence.
Link to first part of The Lumentum Series:
The Lumentum Series | Part 1: Transceivers

Lumentum. A $25b market cap Nasdaq-listed AI infrastructure company that according to their 10-K is a “leading provider of optical and photonic products” whose products “are essential to a range of cloud, artificial intelligence and machine learning (“AI/ML”), telecommunications, consumer, and industrial end-market applications.”
Outline
Data Center Networking Backgrounder
Benefits of CPO
Reliability is Proven but Adoption is Delayed
The Light Source Requirements of CPO
The Competitive Landscape: Coherent Left in the Dust
The Operating Model: Co-Packaged Omnipotence Brings Co-Packaged Outperformance
Bonus Section: Modeling Traditional EML and CW Laser Revenue
Data Center Networking Backgrounder
Let’s do a thought exercise. If you wanted to train an AI model that required X GPUs, how would you connect those GPUs in your own datacenter?
The most simple approach is to directly link each chip to all other chips it needs to communicate with.
But this works only for the first 10 chips. Because each chip has to communicate to every other chip (during the “all reduce” operation) in order to complete the model training, connecting X GPUs requires a number of links that scale at O(n^2). This is not scalable.
Therefore, the industry devised modern datacenter networking architecture: Scale Up, Scale Out, and Scale Across.
First is scale up. This refers to the lowest level of networking, connecting individual chips together inside of one rack to act as one giant brain. This has only been done with copper so far. The main protocol here is Nvidia’s NVLink. Scale up handles monstrous amounts of bandwidth because the signal does not have to travel far.
Next is scale out. This refers to connecting many scale up “pods” together, routing signals to and from them from a central switch. Scale out has already adopted optical—this is where pluggable transceivers have lived. Infiniband and Ethernet are your two choices here. The signal has to travel a lot farther, so it must be prepped and corrected a lot before departure and upon arrival with power-hungry chips. This means the bandwidth it can handle is lower.
Finally, we have scale across, which is simply that when we reach the power limits at one site, we have no choice but to build an entirely new datacenter and send our signal there.
Benefits of CPO
Before I explain CPO, I will first explain very simply the geography of a circuit board. Historically, silicon chips are packaged strictly with their logic components, while the communication component (optical transceivers) lives in a completely different neighborhood at the edge of the server rack (the faceplate). Data from the GPU has to travel as an electrical signal across the PCB (motherboard) to reach the transceiver. This journey is only a few inches, but a few inches is a looooooooooong distance. This journey degrades the signal so badly that every transceiver requires a specialized, power-hungry chip called a Digital Signal Processor (DSP) just to clean it up (these DSPs are what make Marvell a $70b company). They hog nearly half of the power of a transceiver. DSPs are therefore public enemy #1.
CPO eliminates the signal’s annoying morning copper commute to the pluggable train station so it can stay healthy and happy. No more degradation and no more DSP. Instead of stranding the optical engine at the edge of the board, CPO mounts the optics directly onto the same package substrate as the GPU or Switch ASIC itself. It effectively integrates the “modem” into the “processor.” By relocating the optical conversion point to within millimeters of the compute silicon, the electrical signal no longer has to traverse the entire circuit board. The result is a chip that doesn’t just process data but natively “speaks” light, dramatically reducing the power and latency penalties of the old electrical transport layer.
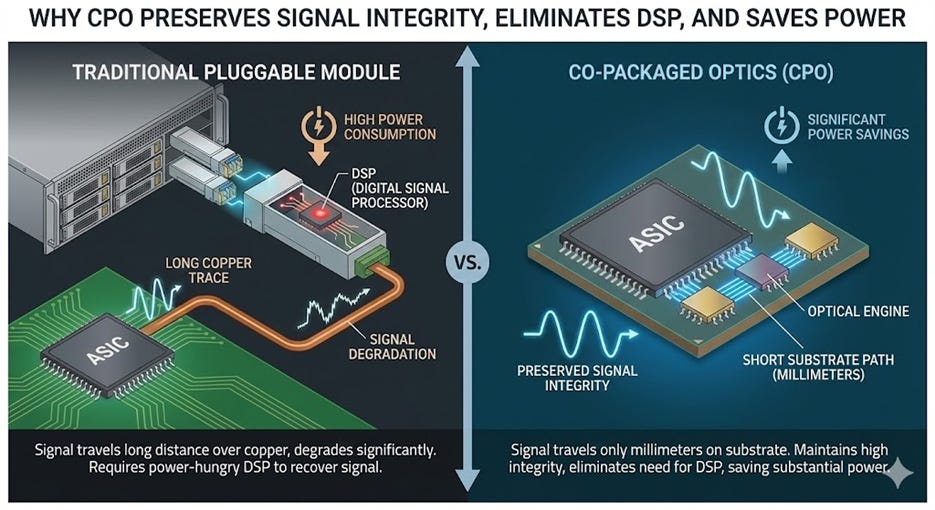
CPO is able to benefit both scale up and scale out. People are most excited about scale up because optics historically have never been used there, so it’s a capability unlock. You can’t plug a transceiver into the inside of a rack. And at the Rubin generation and beyond, insane speeds like 14.4 Tbit/s finally expose the limitations of copper. Plus, scale-up is a much larger TAM for networking vendors since there are just that many more links.
The advantage for scale out is less capability and more TCO. CPO reduces the power required to transmit data by roughly 73% compared to traditional transceivers. An 800G DSP transceiver consumes 16–17W, whereas an equivalent CPO optical engine (plus external laser) consumes only 4–5W.
Reliability is Proven but Adoption is Delayed
To state a fact, CPO is good tech.
CPO reliability has already been proven to be superior to traditional pluggables. A recent study by Meta and Broadcom logged over 15 million device hours on CPO switches with zero unserviceable failures, demonstrating a mean time between failures (MTBF) of 2.6 million hours—nearly 5x better than the 500k-hour MTBF of standard 400G transceivers.
What’s actually stopping CPO adoption currently?
First is serviceability. In a traditional pluggable setup, if a laser dies, a technician simply… unplugs the pluggable and plugs a new pluggable in (aptly named component). In a CPO architecture, a component failure can impact 64+ ports, potentially rendering an entire switch unusable or requiring a complex, “open-box” surgery. This operational shift turns a routine $1,000 repair into a potentially catastrophic infrastructure event.
Second is power savings dilution. While CPO dramatically reduces the power consumption of the optical link itself—cutting energy use by 73% compared to DSP-based pluggables—networking only accounts for roughly 9–15% of a total AI cluster’s power budget (dominated by thirsty GPUs), so switching to CPO yields only a marginal reduction in total cluster power.
Third is vendor lock-in. There is only one thing the Chinese manufactures more efficiently than cheap toys, and that is pluggable transceivers. In that market, buyers can pit Innolight, Eoptolink, and Coherent against each other for a race to the bottom (sorry Coherent). However, CPO consolidates the optical engine into the switch ASIC, surrendering pricing power to one dominant player like Broadcom or Nvidia at a time.
Nvidia’s own roadmap highlights the intense pressure to extend the life of copper. For its upcoming Rubin generation, Nvidia is going to extreme lengths—such as developing novel bi-directional SerDes and massive “Kyber” racks—to keep scale-up traffic on copper. The incentive is simple: copper is still cheaper, lower latency, and avoids the supply chain immaturity of CPO. Additionally, the industry is grappling with a lack of standardization and the immense difficulty of manufacturing CPO at scale, which requires managing fiber coupling and thermal isolation in ways standard electronics fabs are not designed for.
This is why there is still FUD over CPO.
However, these barriers are temporary because they are intrinsically not structural factors. The passage of time will alleviate many of them. The “copper ceiling” is real, and that is structural because it’s the laws of physics.
We cannot keep increasing scale-up bandwidth using copper forever. We cannot rely on scale-out transceivers forever. There will be a tipping point where the industry is dragged on its feet and forced into adoption.
The Light Source Requirements of CPO
Now for the fun part. We’ve been talking about CPO for so long everyone fell asleep. Why does it actually matter for Lumentum?
It matters because the types of lasers required for CPO created a new market where Lumentum is the monopoly.
In the world of standard pluggable transceivers, the laser has a relatively easy life. It sits in a module at the front of the server rack, comfortably far away from the inferno of the main compute chips. Because it lives in this temperature-controlled “suburb” of the server, it doesn’t need to be particularly robust—a standard Continuous Wave (CW) laser putting out 70mW–100mW does the job perfectly. It’s effectively a commodity light bulb, costing roughly $5 to $25, and there are plenty of suppliers who can build them.
But for CPO we move the optical engine directly next to the GPU, right into the heart of the heat. The problem is that lasers are physically allergic to heat; high temperatures degrade their performance and kill their lifespan. You simply cannot glue a heat-sensitive laser diode next to a Blackwell GPU that runs hot enough to boil water. So, the industry reached a compromise: “Co-Packaged Optics” does not mean “Co-Packaged Lasers.” While the modulator moves onto the GPU package, the laser gets evicted. It is moved to a separate, air-cooled box on the rack faceplate called the External Laser Source (ELS).
This separation creates a physics problem. Because the laser is now “remote,” its light has to travel through an extra obstacle course of fibers, blind-mate connectors, and splitters just to reach the GPU before it can even start carrying data. A standard 70mW laser would be too dim to survive this journey. To overcome these losses and often power multiple optical engines at once (to save space), the ELS demands an Ultra-High Power (UHP) laser capable of pumping out 300mW to 400mW per diode. These are serious lasers.

Turns out it is Lumentum and only Lumentum that is good at making serious lasers. Ramping a tiny chip to 400mW creates immense thermal density that destroys standard materials. If the crystal structure isn’t perfect, the laser suffers Catastrophic Optical Damage (COD)—essentially, the power becomes so intense that the laser melts its own mirrors and self-destructs. Preventing this requires “pristine epitaxial growth” and thick, complex crystal stacks that require specialized MOCVD reactors to manufacture. (Shoutout to Aixtron and shameless plug to Aixtron report below) It is an exponentially harder manufacturing challenge than standard lasers, and right now, Lumentum is the only “arms dealer” with the capacity and yield to deliver them at scale.
The Aixtron Series | Part 2: The Optoelectronics Supercycle

Hope everyone enjoyed their Christmas!!! Thank you to anyone who subscribed or pledged. It means the world to me that you found my research helpful and wanted to support.
The Competitive Landscape: Coherent Left in the Dust
Lumentum has a twin. Its name is Coherent.
Coherent is the vertically integrated scale powerhouse. They have transceiver volumes that are multiples of what Lumentum ships and make most of the parts in-house through a supply chain they control.
Who wins in CPO?
As of today, Coherent is approximately two years behind in the development of UHP lasers. This lag isn’t just a matter of production volume; it is a fundamental yield and reliability crisis. While Lumentum is already shipping 300mW–400mW lasers that meet the grueling GR-468 reliability standards required for AI clusters, Coherent is struggling to stabilize these high-power chips without them suffering from thermal degradation.
To add insult to injury, Coherent is still ordering EMLs from Lumentum instead of producing it themselves. The fact that Coherent—a laser company—is reportedly still buying EMLs from Lumentum to fulfill its own transceiver orders serves as a smoking gun: if they cannot even yield enough standard EMLs, their ability to manufacture the exponentially harder UHP lasers is highly suspect.
So although Coherent leads in scale, Lumentum leads in capability. Thus, Lumentum is simply fighting a much, much easier battle. Coherent is basically stuck until they can figure their shit out. For Lumentum, capacity constraints are easier to overcome; they have the recipe, all they have to do is bake more cakes. Let them cook.

The Operating Model: Co-Packaged Omnipotence = Co-Packaged Outperformance
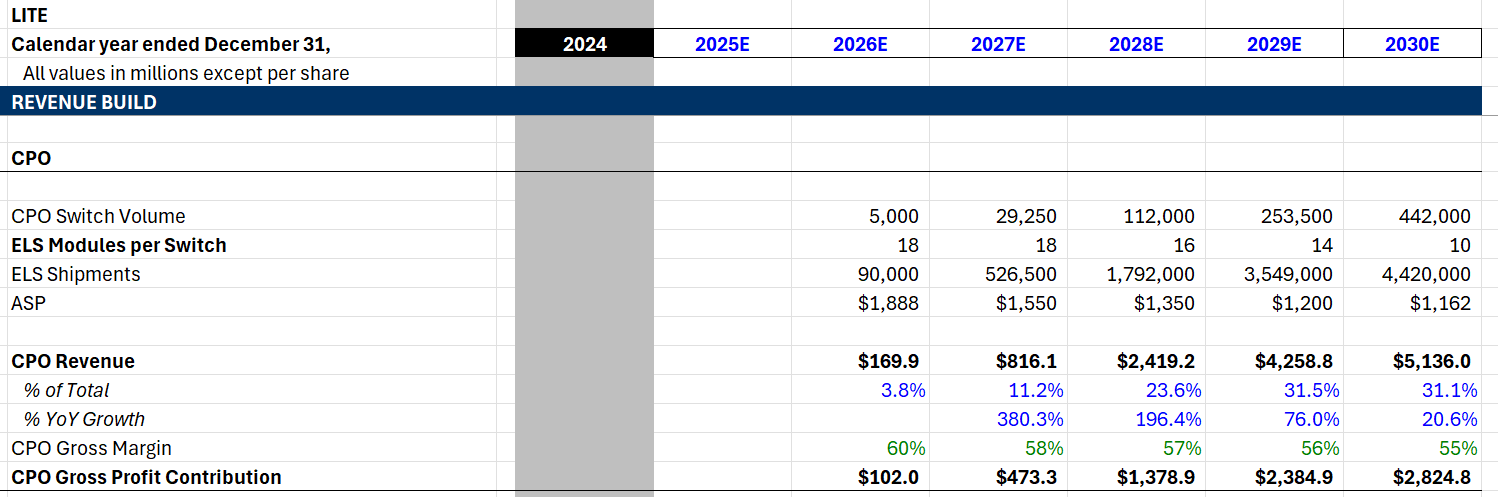
I like going really granular and thinking from first principles when doing my revenue builds. That means I might be very off from consensus or just inaccurate, but oh well. The point of modeling is to practice how to think about a business not to crystal ball the future. Furthermore, I have no reason to resist being bullish or avoid bias. Instead of purposeful conservatism, I express my full views through the model, then only assign an investment positive risk/reward if my “biased” case delivers truly amazing returns. If it’s only average, I know there’s a problem.
Our fundamental unit of deployment today is the CPO-compatible switch system (like Nvidia’s Quantum-X800 series), where CPO actually attaches. It is the number of CPO-compatible switch systems that directly determines the number of ELS models needed. For 2026, we project shipments of 5000 CPO-enabled switch systems, primarily driven by Nvidia’s initial ramp of the Quantum-X800 Q3450 chassis. CoreWeave, who has planned to introduce advanced Nvidia networking sooner than peers, could make up as much as half of these shipments. This assumption is validated by an upper demand limit of 12,500 according to recent work by SemiAnalysis.
Our 2027 switch shipment estimate of 29,250 is derived from a 15% CPO attach rate on industry-wide shipments of 195,000 switches. Our 2028 estimate of 112,000 is based on hitting the copper wall during the Feynman generation, requiring 40% of switches to adopt CPO for scale up. By 2030, we forecast 442,000 CPO switch shipments a year, driven by growth in both overall switch volume and CPO penetration rate.

Once we have the switch volume, we must ask: How many ELS modules? The current architecture for a 144-port Quantum-X800 switch requires 4 switch ASICs and 18 ELS modules to provide the necessary redundant power for the optical engines. This multiplier effect is powerful: selling just one switch generates 18 unit sales for Lumentum. We model this intensity remaining flat at 18 modules through 2027, then slightly decreasing to 16 modules per switch by 2028 as the power output per laser diode increases (allowing one laser to drive more lanes). By 2030, the average attach rate is forecast to fall to 10 ELS modules per switch system. Unlike current generation lasers that provide 8–16 wavelengths, these next-generation “Guide-class” sources use programmable comb laser technology to aggregate hundreds of wavelengths into a single package. This allows a single ELS module to drive significantly more optical engines, creating a “Ratio Collapse” where fewer, higher-value laser modules are needed even as total switch bandwidth scales to 102.4T and beyond.
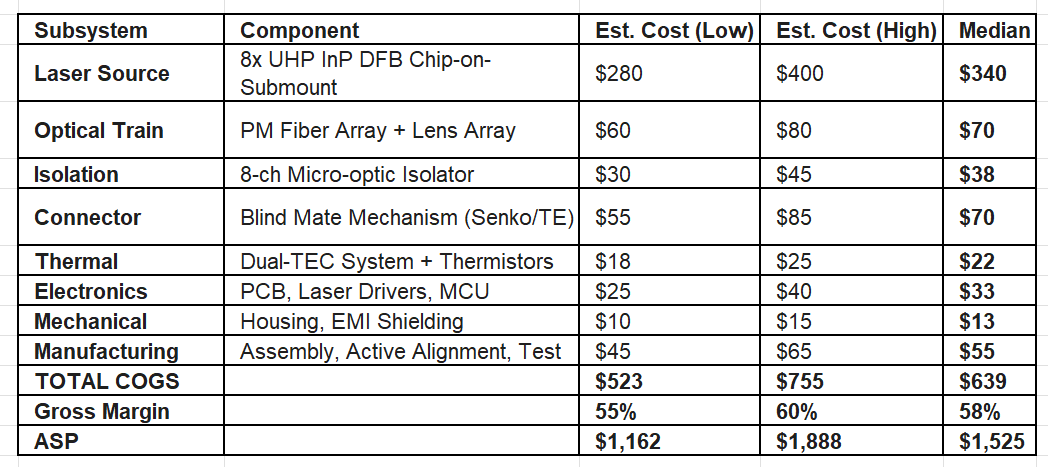
The third layer is the Average Selling Price (ASP). To get to our ASP, we have to do the BOM math. It starts with the UHP laser, which we estimate costs $35-50 per chip due to the low yields and manufacturing difficulty. This lines up with management commentary; they explicitly stated UHP lasers are multiples of the lower power commodity CWs which are $5-6. An ELS module requires redundancy and power, so it packs 8 of these diodes inside, creating a laser cost range of $280-$400.
The rest of the BOM consists of non-laser components and manufacturing costs, such as the optical train, isolator, connector, etc. For each component, we make a high cost (low volume) and a low cost (high volume) BOM assumption. By aggregating the high-end costs and applying a 2026 gross margin of 60%, we arrive at our starting ASP of $1,888. We assume this price erodes by ~10% annually as volume scales and efficiencies are passed to customers, landing at roughly $1,350 by 2028 and our low end $1,162 by 2030. Even as Coherent eventually enters the market in the late 2020s, the extreme difficulty acts as a margin floor, likely keeping this segment above 55% through the end of the decade.
In the end, revenues in 2027 are solid but nothing extraordinary. $800mm is likely behind what they will make in OCS revenue that same year. However, this nearly triples once we hit that bandwidth wall in 2028 to $2.4b, continuing its growth to $5.1b in 2030. We forecast that Lumentum’s CPO revenue alone 5 years from now will eclipse its entire revenue base this year.
Our results are clear: Lumentum’s Co-Packaged Omnipotence in Co-Packaged Optics shall bring investors Co-Packaged Outperformance.
Bonus Section: Modeling Traditional EML and CW Laser Revenue
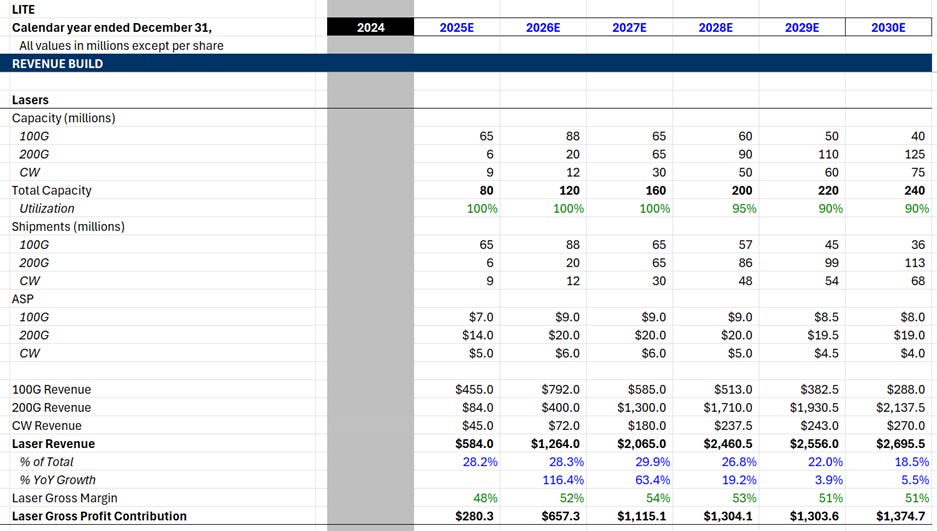
Now it’s time to forecast Lumentum’s legacy laser business. This segment is not as exciting as CPO, but still very interesting right now. Namely, I think there is going to be a major shortage in 200G EMLs next year.
Firstly, what is on the laser menu? EMLs and CWs.
EML (Electro-absorption Modulated Laser): These are integrated chips that combine the light source and the modulator (the “shutter”) into a single component. Because they can modulate light at extremely high speeds directly on the chip, they are the standard for high-performance 100G and 200G-per-lane transceivers (OSFP/QSFP-DD).
CW (Continuous Wave) Laser: These lasers emit a constant, unmodulated stream of light. They are primarily sold to Silicon Photonics (SiPh) customers who use a separate modulator on their own silicon chip to encode the data. They are lower in complexity and cost compared to EMLs (so more commoditized).
One minor drawback of the laser business is its capital intensity. InP laser manufacturing requires specialized fabs and MOCVD reactors that take months to install and qualify. That’s why we gotta model this segment like a foundry—capacity and utilization and ASP. Lumentum is currently fully allocated (100% utilization), shedding customers because the supply/demand imbalance is so awful, and is undertaking a 40% capacity expansion over the next several quarters, which includes a migration from 3-inch to 4-inch InP wafers. Our model reflects this constraint, capping revenue growth by the pace of this physical ramp and assuming utilization rates remain pinned near 90–95% through 2030.
The most immediate catalyst for this segment is the transition to 1.6T transceivers, which require 200G/lane EMLs. A 200G EML commands a ~2x ASP premium over a 100G EML, yet it occupies roughly the same footprint on the wafer. So, Lumentum has every reason to be shifting capacity away from 100G and into 200G, which is reflected in our model. This mix shift is pure margin accretion. Furthermore, because industry-wide InP capacity is so tight, basically every sell side analyst and their moms know that management is signaling “double-digit” price hikes for these chips in 2026. We model 200G EML ASPs starting at $14 and getting hiked to $20 in 2026 and then holding up better than historical norms due to the lack of viable second sources (sorry Coherent).
We expect gross margins for this segment to peak at 54% in 2027 as the mix shift from 100G to 200G EMLs coincides with the depths of the shortage, while sliding back to 51% in the out-years. We project this segment to contribute $2b in revenue for 2027 before seeing modest but healthy growth to $2.7b in 2030.
This article is super interesting and I assume you are right that Lumentum is in a good position on CPO, at least for now. However, I am concerned that "CW lasers combined with silicon photonics has become the main alternative route for CSPs facing EML shortages.," per Trend Force.
https://www.trendforce.com/presscenter/news/20251208-12823.html
Is it possible that while Lumentum may hold a dominant position for the moment on CPOs, it may face a growing threat from silicon photonics more generally (given that as you note CW is more commoditized)?
And even in CPOs, are Broadcom and Marvell likely to be competitors? I think I read somewhere that AWS is working with them on CPOs, although I don't know how comparable they are as potential competitors in the photonics space.
Jason,
I enjoyed this article. Many thanks for the discussion on the laser position relative to the GPU.
I wrote an article on Halma plc, which discusses their Avo Photonics unit. You might find of some interest.
https://rogerbreuer.substack.com/p/halma-plc-from-tea-plantations-to?r=1qxcim