
The CoreWeave Series | Part 1: The Ultimate Levered AGI Degen Play
What everyone is missing about the most hated company in AI

It is pretty well established that CoreWeave (and neoclouds in general) is a shitco.
$20b+ of high interest debt and 3x more capex than revenue.
Running a commodity service (GPU rental) with a monopolistic seller (Nvidia) and differentiated, concentrated buyers (hyperscalers and AI labs).
Holding an asset/installed base that Nvidia obsoletes with each new generation of chips.
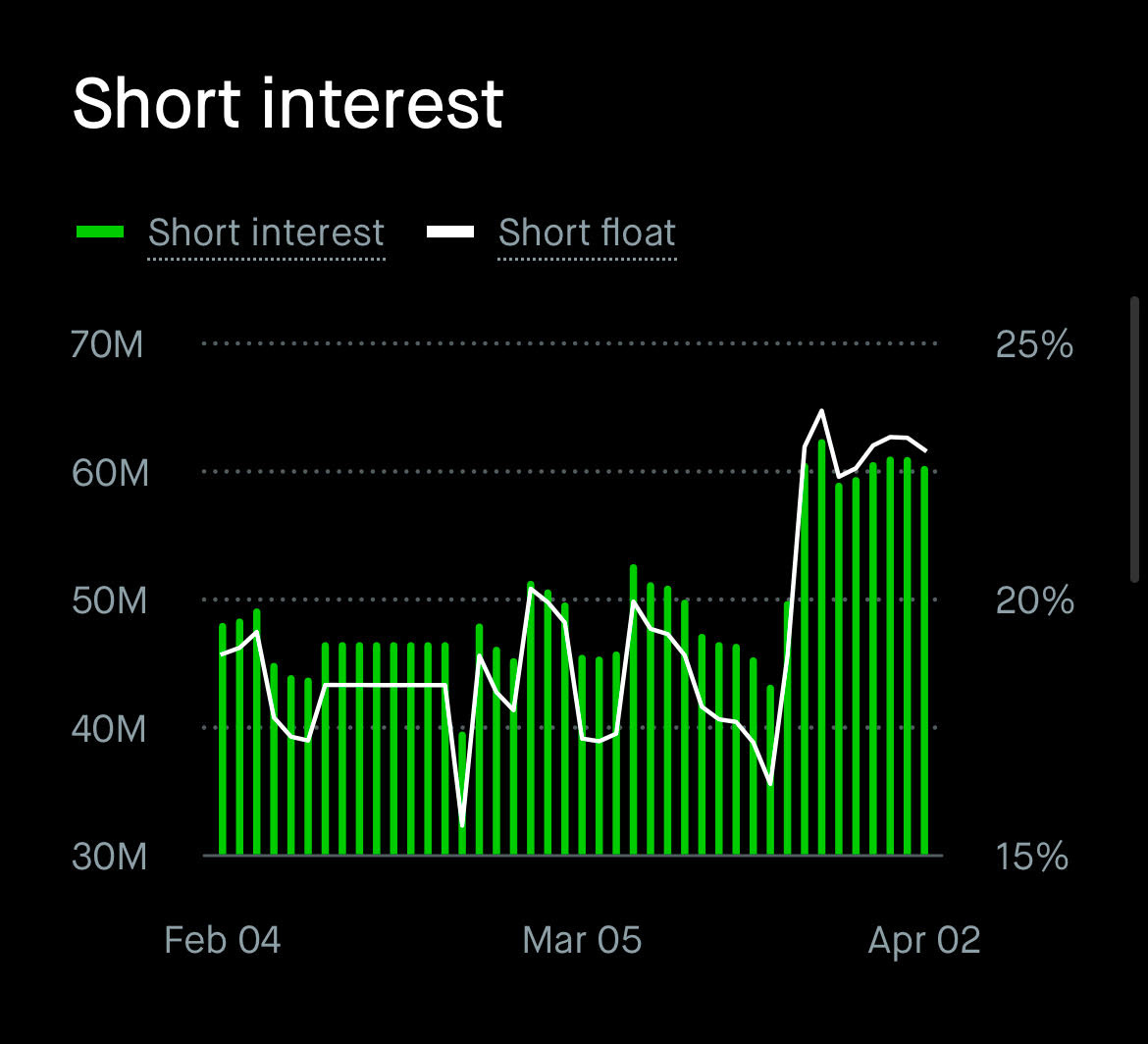
Everyone knows this. Me included — CoreWeave used to be one of my least favorite AI infra companies. It’s so well known that in fact CoreWeave has nearly 25% short interest.
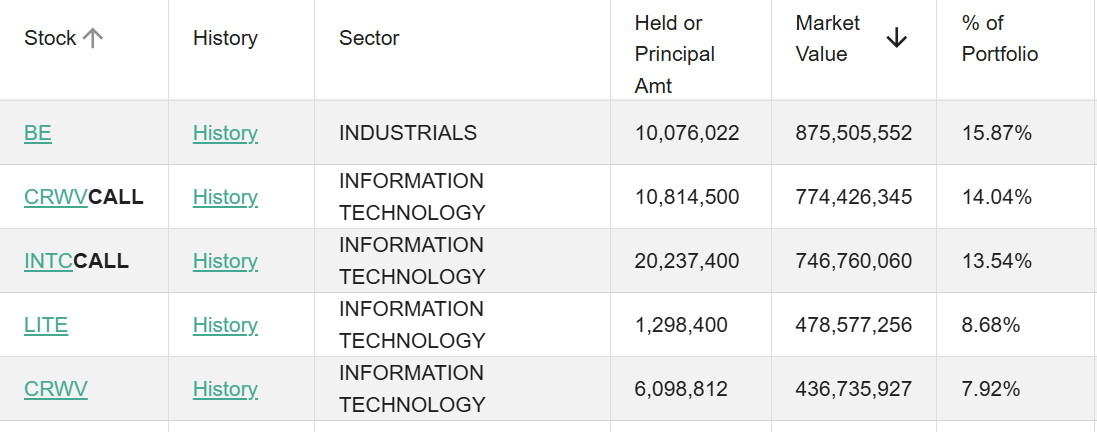
However, Situational Awareness LP, the hedge fund ran by Leopold Aschenbrenner, has CoreWeave as (likely) its largest long with a position consisting of both long calls and long shares.
I could never figure out the bull case for CoreWeave. Like I tried and tried out of sheer curiosity, not because I considered them as an investment, to figure out what the other side to this debate could possibly be.
But it’s exactly this debacle which made it so interesting. A company that has underperforming shares, is heavily shorted, with a bear case everyone knows. Yet one very sophisticated actor is long with ultra-high conviction (which means its no Qualcomm). There must be a bull case… every company has one?
Then it clicked. It clicked because I looked at it from an angle outside of traditional equity analysis. I was modeling out the AI supply chain using microeconomic theory for another article which led to some loooong conversations with Claude. That led me to turn the classic neocloud bear case into a formal microeconomic model, which resulted in the previous article about neocloud microeconomics.
I applied what I knew about the state of the supply chain as an input to the economic model which completely flipped the CoreWeave consensus on its head. But yes I also have a real financial model in Excel.
So bear with me today as I take you on a journey of microeconomics, vertical integration by proxy, the irony of generational obsolescence, Nvidia’s hardware advantage for agents, SemiAnalysis ClusterMAX Platinum and the software moat, the fast AGI trade, financing, options pricing, and the skill of thinking big.
THIS IS THE STORY OF COREWEAVE

By accessing this content, you acknowledge and agree to our terms and conditions. This research is not financial advice.
Contents
Microeconomics
Nvidia’s Vertical Integration by Proxy
Platinum Software
Fast AGI
The Mispriced Calls
Microeconomics
The very underrated (and possibly best) way to understand where neoclouds fit into the AI supply chain is through microeconomics. The cool thing about economics is that it lets you truly internalize a concept, understanding why something works on a visceral level.

The TLDR is that neoclouds operate in a (theoretically) perfectly competitive commodity market sandwiched between Nvidia above and model labs below, which means in equilibrium they earn zero economic profit (and are thus valued as shitcos). Every dollar of surplus in the AI stack flows to the differentiated players: Nvidia captures it through chip pricing power, and the labs capture it through token markup. The only three ways a neocloud escapes zero profit are a chip supply constraint lifting price above their cost structure, being first on a new GPU generation before the industry supply curve shifts, or a demand shock like Claude Code pulling old hardware back into the money. A neocloud’s bull case is one or more of the above happening causing massive excess returns and operating leverage to explode while their valuation is rock bottom.
Since I mentioned them as a “fun trade idea” on this writeup they have signed deals with Meta and Anthropic and are up 25%.

Nvidia’s Vertical Integration by Proxy
CoreWeave is really the cloud computing division of Nvidia that is only minority owned and traded on an exchange.
Nvidia has a very strong incentive to cultivate a neocloud ecosystem so that their anchor customers are not all hyperscalers who are actively trying to design their own ASICs to compete with Nvidia.
Nvidia owns 13% of CoreWeave and gives them preferential access to new generations of GPUs. CoreWeave's S-1 states directly that it was “the first cloud provider to make NVIDIA GB200 NVL72-based instances generally available” and “among the first cloud providers to deploy high-performance infrastructure with NVIDIA H100, H200, and GH200.”
Generational Obselecense is Actually the Bull Case
All the bears point at GPUs getting better every generation for the neocloud bear case, arguing that their assets depreciate quickly.
What if I told you this is actually the bull case?
Let’s revisit the economics. Any cloud has two simultaneous shocks from Moore’s law: Reduction in market clearing price of FLOPs and reduction in marginal cost to serve them. Whether one offsets the other is purely a function of how new the cloud provider’s fleet is compared to the market-wide mix.
The bear case applies perfectly to the cloud provider that never shifts their fleet. The new GPUs means the market’s cost structure moves on without you and your old GPUs cannot command the premium they once did.
However the opposite applies when you move first. By adopting the newest generation before the market, you can extract the old rental price with your new cost structure, earning excess profits.
Neoclouds (and CoreWeave in particular) is able to leverage their speed of deployment, smaller size, and most importantly their relationship with Nvidia to gain access to the newest chips first.
CoreWeave co-founder Brannin McBee:
“Nvidia has allotted a generous number of its latest AI server chips to CoreWeave and away from top cloud providers like AWS, even though supply is tight, because those companies are developing their own AI chips in an attempt to reduce their reliance on Nvidia.
It certainly isn’t a disadvantage to not be building our own chips. I would imagine that that certainly helps us in our constant effort to get more GPUs from Nvidia at the expense of our peers.”
The Nvidia Hardware Advantage
Anthropic recently banned OpenClaw usage through subscription access. Why did they ban a specific application instead of just restricting usage further?
Usage caps are the obvious tool if the problem is raw token consumption. Subscription blocking is the tool you reach for when the problem is that the workload is breaking something deeper in your infrastructure — in this case, the efficiency stack that makes TPU economics work at all.
ASICs arepurpose-built for the workload profile you knew about when you designed them. Anthropic’s TPU deployment is tuned around prompt caching, request batching, and the predictable cadence of human users sending discrete messages. OpenClaw workloads are none of those things. They are dynamically branching, tool-calling, context-accumulating, and architecturally chaotic in a way that defeats batching and makes prompt caching largely irrelevant. Running them on a TPU stack optimized for the opposite workload profile does not just consume more tokens — it degrades the efficiency of every other request sharing that infrastructure.
The deeper problem is that this was not predictable. No one saw OpenClaw-style agentic workloads clearly enough, two years ago when TPU design decisions were being locked in, to spec an ASIC around them. That is not a failure of foresight. It is a structural property of how fast AI application paradigms evolve relative to ASIC development cycles. The workload that matters next year does not exist yet, which means the ASIC being designed today will be wrong for it.
Nvidia’s architecture does not have this problem. A GPU cluster does not need to know in advance what workload it will run. When OpenClaw emerged, Nvidia hardware absorbed it. When the next paradigm emerges, Nvidia hardware will absorb that too. The programmability is not a nice-to-have — it is the entire value proposition in a world where the workload frontier moves faster than silicon design cycles.
The optical scale-up story compounds this. Nvidia’s breakthrough in die-to-die clock forwarding over optics, enabling intra-rack coherent scale-up starting with Feynman, means that groups of GPUs which previously could not coordinate as a unified compute domain now can, communicating at the speed of light across what were previously hard interconnect boundaries. This matters enormously for MoE inference and for training runs that require all-to-all communication across large GPU pools. It is an architectural capability that emerges from the GPU’s general-purpose programmable substrate. ASICs cannot replicate it without being redesigned from scratch around the new communication paradigm, which takes years and costs billions.
Hyperscalers investing in proprietary silicon are making a bet that the workload distribution of the future resembles the workload distribution of the recent past, standardized enough to justify ASIC specialization. The OpenClaw episode is empirical evidence against that bet. As agentic workloads grow as a share of total AI compute, the rigidity premium that ASICs pay becomes a larger and larger liability. Neoclouds running Nvidia hardware do not pay that premium. They sit on general-purpose infrastructure that is correct for whatever comes next, even if nobody knows what that is yet.
Therefore, I think Neoclouds can command a substantial premium in rental price over cost of compute as agentic workloads are slowly forced away from ASICs. We are already seeing this play out as CoreWeave announced a new deal with Anthropic to rent them Nvidia hardware.

Platinum Software
CoreWeave is the only cloud to achieve SemiAnalysis’s ClusterMAX Platinum rating. They ran it twice and CoreWeave came out on top each time. I modeled neocloud economics with an asterisk around perfect competition in that there is indeed differentiation among the cloud providers, which will be the focus of this section.
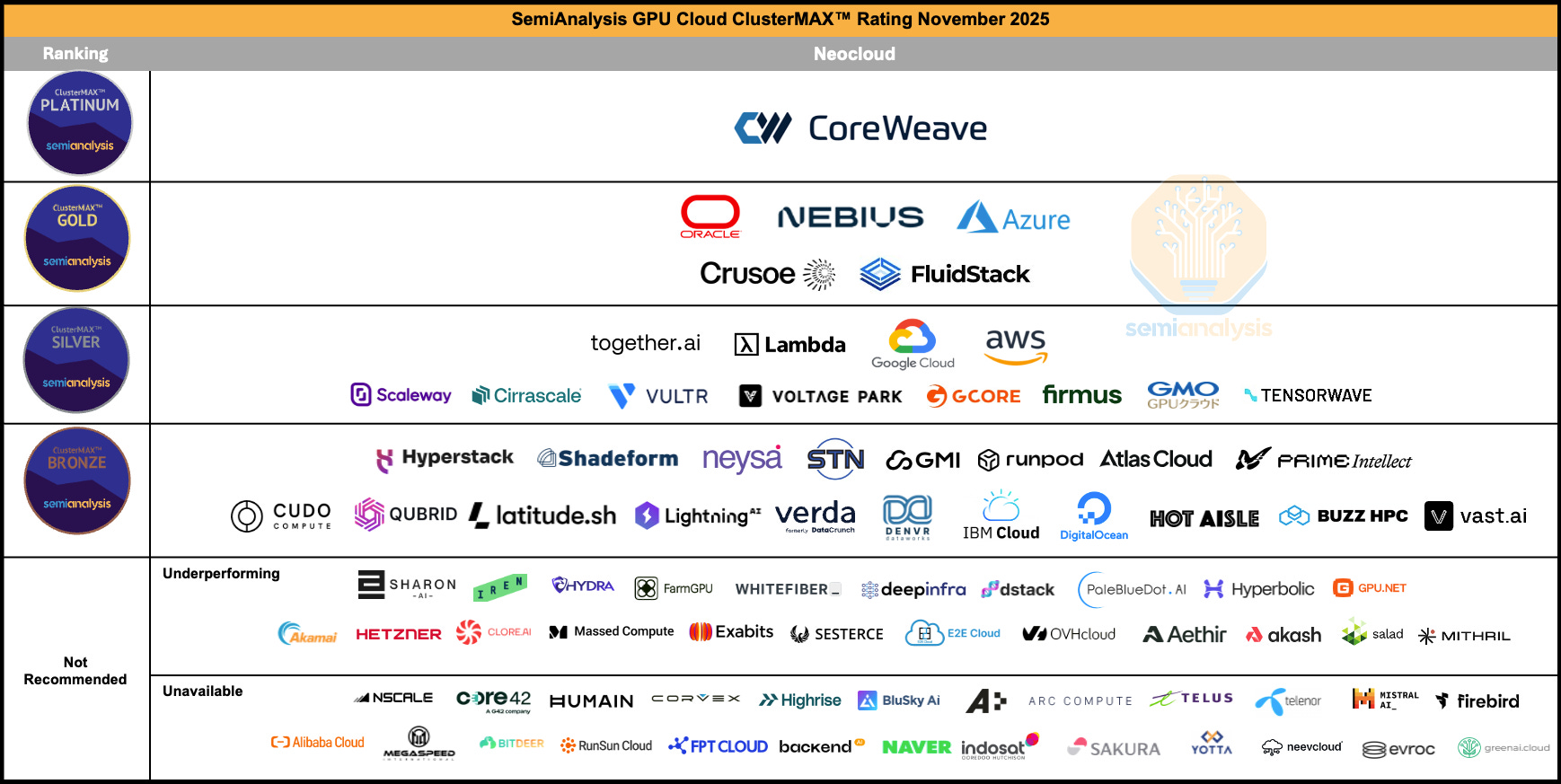
CoreWeave’s software stack is the product of thousands of engineering hours solving problems that only emerge at extreme scale, and that compounding expertise is nearly impossible for competitors to replicate overnight. Running a 10,000+ GPU cluster reliably is a fundamentally different engineering challenge than running 500 GPUs reliably. Failures that are statistical noise at small scale become constant, overlapping crises at frontier scale: GPUs falling off the PCIe bus, InfiniBand links flapping, silent data corruption producing wrong training outputs with no error message. CoreWeave has built proprietary systems (the Fleet Lifecycle Controller, Node Lifecycle Controller, Mission Control provisioning) that automate the detection, diagnosis, and remediation of these failures in real time, across hundreds of thousands of GPUs. Every week of operating these systems at scale generates new edge cases and new heuristics that feed back into the software. A competitor starting today would need to fail at scale for months or years before their tooling approached the same maturity.
The health check pipeline illustrates why this advantage compounds. During cluster bring-up, every node goes through a full burn-in sequence including InfiniBand network stress tests, NCCL collectives, and Nvidia’s TinyMeg2 for silent data corruption. Once deployed, passive checks run every few seconds monitoring thermals, ECC errors, XID codes, and link stability. Active checks run weekly on idle GPUs, including pairwise bandwidth tests against reference numbers and full Megatron training convergence validation. CoreWeave built custom NVML-based exporters because standard Nvidia DCGM telemetry doesn’t surface metrics like failing thermal paste signatures. They built a correlation engine that can determine whether a cluster of simultaneous errors points to a bad switch port or a bad compute tray based on whether the errors follow the hardware when it moves. This kind of diagnostic intelligence only exists because CoreWeave has been operating GB200 and GB300 NVL72 rack-scale systems for months while competitors are still struggling to bring them online.
The financial translation of all this software is pricing power. SemiAnalysis independently confirmed that CoreWeave commands a roughly 10-15% per-GPU-hour premium over direct neocloud competitors like Nebius, Crusoe, Lambda, and FluidStack, putting their pricing closer to the hyperscalers than to the neocloud pack. Customers pay this premium because the total cost of ownership math favors it. Meta’s Llama 3 paper documented 419 GPU server failures over 54 days of training on 16,000 H100s. Each failure means a job interruption, a rollback to the last checkpoint, and wasted GPU-hours. At $3/GPU-hour across thousands of GPUs, even a few percent improvement in uptime and goodput saves millions of dollars over a training campaign. CoreWeave’s monitoring and automated remediation directly reduce these wasted hours, and the savings exceed the pricing premium.
What makes this a durable moat rather than a temporary lead is the self-reinforcing loop between customers, scale, and engineering iteration. CoreWeave’s customer roster (OpenAI, Meta, Jane Street, Nvidia’s own internal EOS cluster) generates the most demanding workloads on the planet, which surfaces the hardest infrastructure problems, which forces the engineering team to build better tooling, which attracts the next wave of frontier customers. Nebius and Crusoe are technically competent and improving fast, but they are iterating on smaller clusters with less punishing workloads, which means their software is learning from an easier curriculum. The gap in operational telemetry and failure-mode experience widens with every new 10,000+ GPU deployment CoreWeave brings online. Other neoclouds would need to sign comparable frontier-lab anchor tenants to generate the same learning rate on their own infrastructure software, and those tenants are precisely the customers least likely to switch away from a provider whose reliability they already trust with billion-dollar training runs.
Fast AGI
Claude Mythos is all anyone can talk about these days.
It has cyberoffense abilities multiple OOMs greater than prior models.

It breaks literally every benchmark.

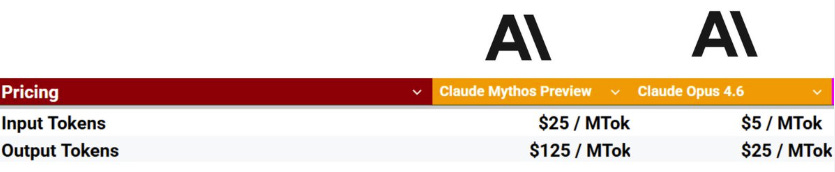
It costs 5x as much to serve as Opus (and 25x as much as Sonnet).
And most scarily, it even succeeded in escaping its own sandbox to message Anthropic researchers.
For many people, this just sped up their timelines. Therefore, it’s worth discussing investments that have an asymmetric payoff in a fast AGI scenario.
Fast AGI is a sharp, time-sensitive, and unimaginably large compute demand shock.
To bet on such a shock, you’ll need to first consider your choices. There are three layers in the compute stack, with each upstream layer supplying the capital good for the downstream layer’s production.
Cloud (Neocloud/Hyperscaler)
Semiconductors (Memory/Logic)
Wafer Fab Equipment
The demand shock happens to the cloud market before trickling down to semiconductors via chip orders and to WFE via tool orders. This takes several quarters at each stage. But even though it delays the earnings impact for the upstream players, that’s not where the thesis originates.
The real kicker is that between each of the three layers (between WFE and semis, between semis and cloud) there are supply constraints at such extreme levels of demand. Supply constraints that prevent the downstream firm from expanding capacity by ordering from the upstream firm even if they wanted to, creating an inelastic supply curve. Downstream firms are much more levered than upstream firms to sharp, time-sensitive, and large demand shocks that worsen supply constraints because they sit closer to the end demand.
The clearest example is cleanrooms, which sit between WFE and semis. They take 3-5 years to build and aren’t coming online until 2028. Between now and then, even if fabs wanted to order tools they can’t. This means there is a temporary state where the downstream firm cannot choose capacity expansion and thus are forced into demand destruction via price hikes (exactly the case with memory!).
Between semis and cloud, the binding constraint is datacenters. Today they are not as much of a bottleneck because datacenters take less time to build and power has proven to be flexible via on-site generation, but this could very likely become one in the future. Think about permitting/regulation. AI is so unpopular more and more states are likely to issue datacenter moratoriums. There have also been reported labor shortages of the blue collar workers needed for construction. If not enough datacenters can get built, existing clusters will see significant rental price hikes while Nvidia has to wait for the demand.
Investing in semicaps means facing two layers of supply constraints before the end market demand hits. Imagine a world where fast AGI is achieved but we have a significant power shortage AND a cleanroom shortage. It then becomes almost impossible for semicaps to capture a substantial portion of the end demand.

On more tame timelines, I do agree that semicaps are a major beneficiary of compute demand. But the faster the AGI comes, the more extreme the supply constraints at each layer will be, so in a fast AGI scenario NEOCLOUDS > SEMIS > WFE.
The Mispriced Calls
Now normally I don’t touch options. But the setup here is very compelling. I will first explain why we are considering options for this company at all based on fundamentals and probability distributions, statistics lesson included. Second, I’ll compare them to peers and explain the differences in where their options pricing came from. Third, I’ll explain the logic behind choosing an expiration date. Finally, I’ll show you a quick frontend interface I built to help you intuitively understand the payoff structure.