
Cerebras Full Investment Analysis (Free)
Technical Foundations (Nightmare Compiler, Yield, PVT Calibration, Pipeline Parallelism, I/O Bandwidth and Memory Constraints) and Investment Analysis (Financials, Real-World Testing, and Bull Cases)

New IPOs are lots of fun! Sadly, retail kinda got screwed with this one, as it was originally priced quite reasonably, but the IPO price was revised upwards by 50% before the IPO, and retail investors could barely get half a share allocated if their broker offered it, and on IPO day itself, the stock doubled from the IPO price at open, which made the first buyable price something like a $100 billion market cap.
But now maybe it is time to trade on fundamentals, which will be thoroughly analyzed via this piece of writing.
Today I will be taking you on an all-inclusive journey. We start from the technical foundations of their wafer-scale engine before evaluating the business and market side of their products. Everything that you’ve ever wanted to know about Cerebras, all in one place.
Contents
Introduction to Dinner Plate Computing
The Tale of Two Cities & The Nightmare Compiler
Wafer-Scale Yield
PVT Calibration
Fast Inference (Tensor vs Pipeline Parallelism)
Memory Constraints
The I/O Bandwidth Problem
Economic Relevance
Financials
How to Think About Cerebras
Testing 5.3 Codex Spark
Bull Case
Conclusion
As a Substacker, I am obligated to say that this is the kind of research that comes with a paid subscription!!
By accessing this content, you acknowledge and agree to our terms and conditions. This research is not financial advice.
Introduction to Dinner Plate Computing

Cerebras is the well-known pioneer of dinner plate computing.
Their foundational premise is that, BIGGER IS BETTER.
Normally, when you order a wafer from TSMC, you slice up your wafer into dies. Cerebras decided to keep all of the dies intact and instead network them together into one really big chip.
These spaces between the dies are called keep-out zones because normally you keep everything out of them because they will be cut up by the diamond saws. In this case, these keep-out zones are the home for complex wiring and networking. This means that Cerebras needed to collaborate intimately with TSMC to develop proprietary IP in order to fill up these keep-out zones with networking.

Throughout their investor materials, they make a plethora of comparisons to traditional computing with a bunch of metrics of stuff that chips do (compute cores, transistors, memory bandwidth, FLOPs), and because their chip is bigger, they can do more chip things.

This can mislead retail investors, as in real life there is always a trade off. Cerebras is simply a computing architecture optimized very differently than traditional GPUs.
The Tale of Two Cities & The Nightmare Compiler
SRAM is the super-fast expensive memory at the very top of the memory hierarchy. Faster than DRAM and even HBM.

This memory is usually made with a logic process and sits very close to the compute.
In a traditional GPU, all of its cores share the same unified pool of SRAM.
However, at a wafer scale, a unified memory pool is physically impossible. Therefore, Cerebras designed each compute core to have its own distributed 48 KB of SRAM. This is very little memory (the entire WSE would only have 44 GB of memory total compared to 13.5 TB of HBM3E for the GB200 NVL72 rack).
I like to think of this as a tale of two cities.
One is a small village with a few hundred residents. In this village, there is a shared library in the middle where residents go to fetch the information that they need. It is very easy for this village to coordinate as any two residents can read the same books.
Another is a nightmarish-looking homogeneous suburbia with 900,000 identical tiny homes. Each house has its own small bookshelf. You can only read the books that are in your own house. As you might imagine, it becomes a nightmare for this civilization to coordinate and communicate any information.

A compiler is the machine that translates human (or agent ha) intent (code) into silicon action. It needs to tell the transistors what to do.
In the village with the shared library the compiler’s job is easy. In the homogeneous suburbia, it’s a nightmare as you would have to write a master schedule that guarantees person number 452,000 has the exact right piece of data placed on their tiny bookshelf at the exact right millisecond and then passes it on to person number 452,001 right as they finish using that piece of data.
Because this hardware fundamentally guarantees the compiler complexity, Cerebras can never achieve the software optimization of NVIDIA. However this does serve as a pretty intense barrier to entry for new wafer-scale competitors.
Wafer-Scale Yield
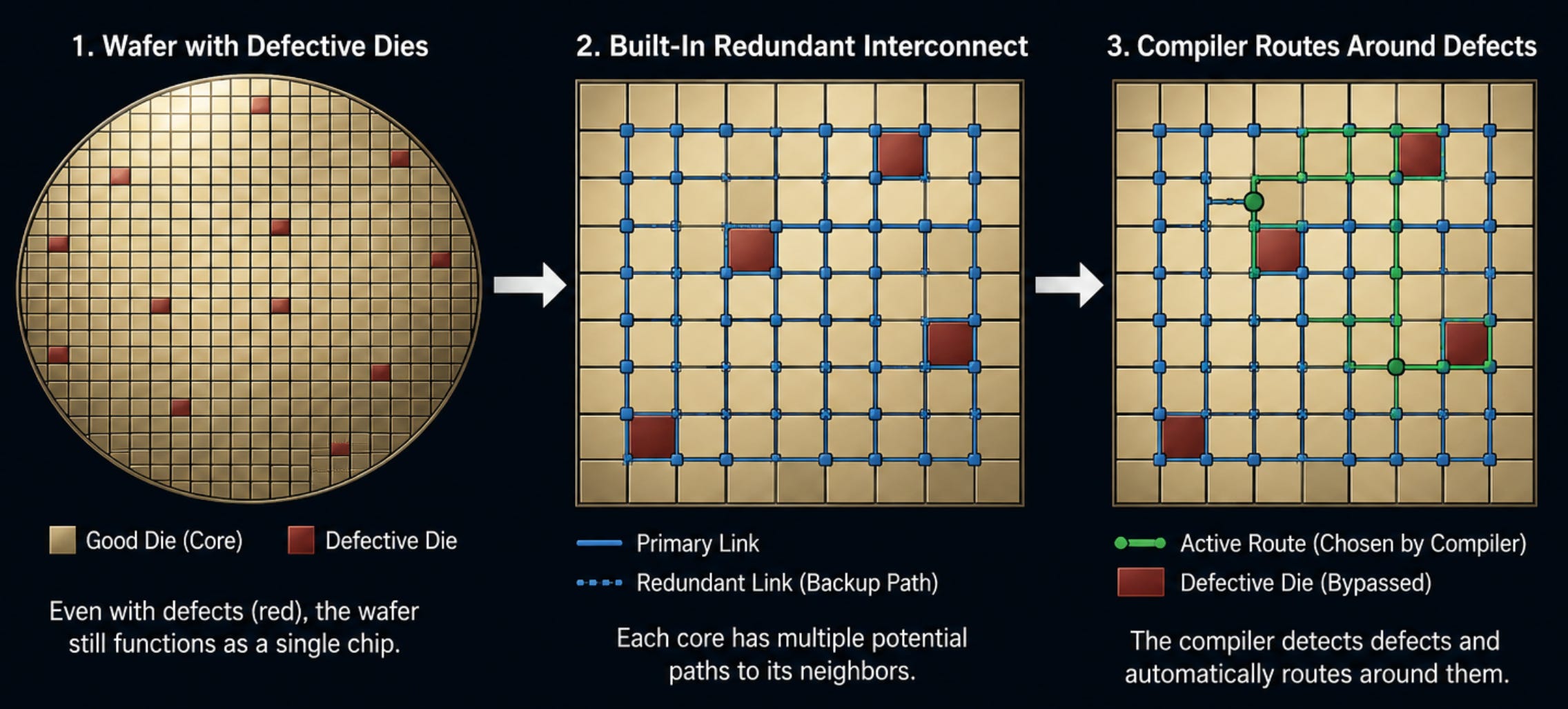
Manufacturing chips is very hard. Sometimes a speck of dust can ruin your chips. Wafer yield is simply the percentage of good dies divided by the total number of dies on the wafer.

No one can ever get close to 100% yield; it’s always somewhere between 50% to a hundred percent.
But wait a minute! Wait a minute. Cerebras is making its chip an entire wafer. If you can never get a hundred percent yield, doesn’t that mean that Cerebras can never get a functional wafer-scale engine? Every single wafer is guaranteed to have at least one defect!
Not at all. Cerebras did a very clever thing where they built in an extra redundant communication pathways between the cores. If they find that a portion of the wafer, a certain die, has a defect, the compiler simply routes around it. This is how Cerebras claims a 100% yield rate on their Wafer-Scale Engines.
PVT Calibration
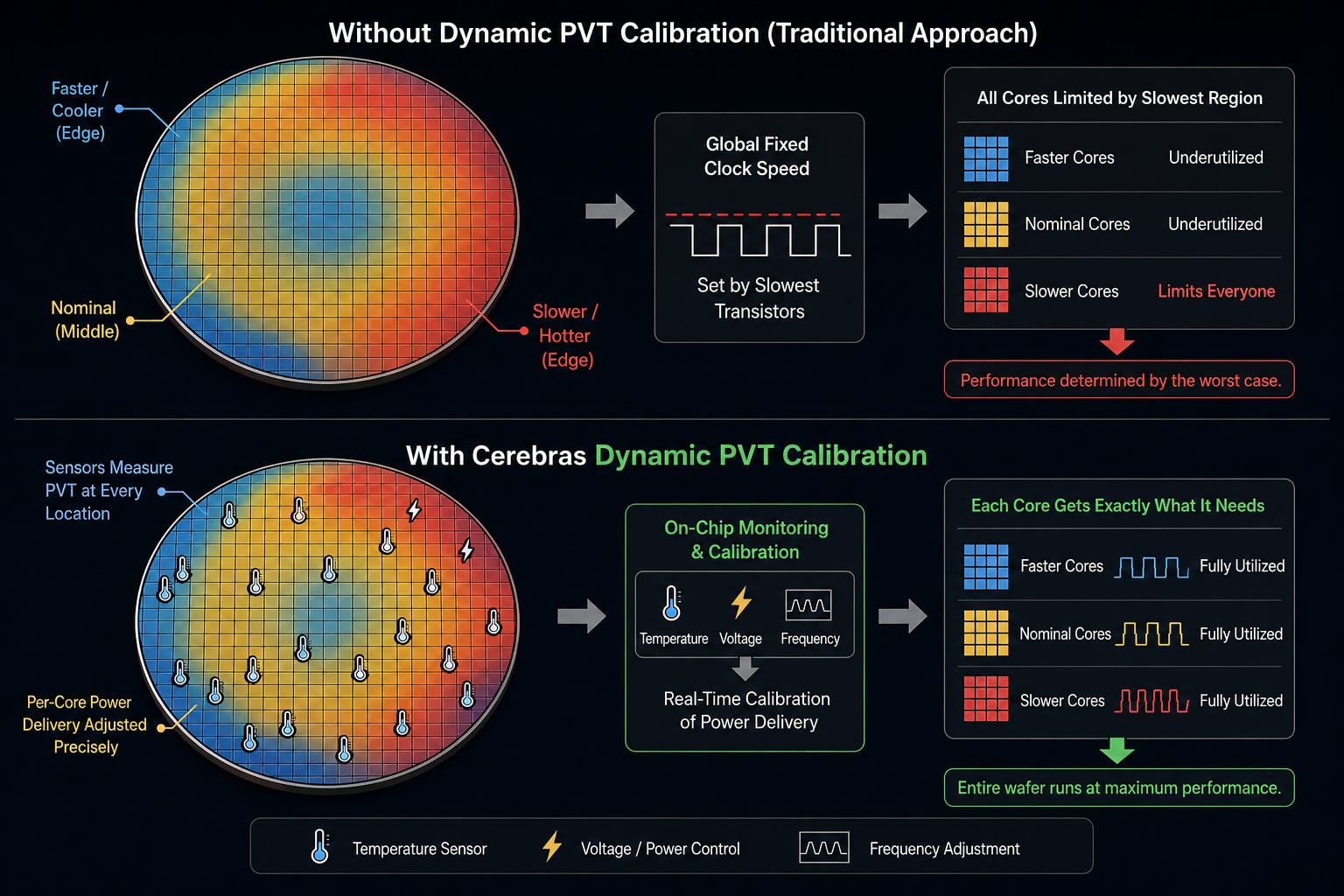
PVT stands for process, voltage, and temperature variation.
Semiconductor fabrication is a highly chemical process. All the etching and depositing and stuff are all done through chemical reactions, even though in diagrams it may FEEL physical.
Because these processes are all chemical, they are never fully uniform across the entire dinner plate. Transistors near the edge may end up switching faster or running slightly hotter than the same transistors located closer to the middle.
Normally, this wouldn’t matter for a traditional GPU because the dies are cut up anyways. But for Cerebras, it becomes a problem because the entire Wafer-Scale Engine needs to be fully synchronized.
This is the exact problem that caused the industry to abandon wafer-scale computing decades ago. If you’re required to clock the speed of the entire Wafer-Scale Engine chip to the speed of the slowest transistors, the performance would be atrocious.
Cerebras, however, developed a system to dynamically recalibrate the entire wafer on the fly. They detect the temperature and voltage and frequency characteristics of every part of the wafer and then actively manage the power delivery accordingly. Basically, every single core gets exactly what they need.
This is by far one of their most important innovations. PVT calibration is a real moat for Cerebras and represents an enormous barrier to entry for Wafer-Scale competitors.
Fast Inference (Tensor vs Pipeline Parallelism)
This is our main course today. Tensor vs Pipeline Parallelism is the single trick up their sleeve which allows them to perform their main value proposition to the market: fast inference.
Tensor Parallelism
Let’s think about how a standard GPU runs inference, called tensor parallelism. Usually, the model weights are too much to fit inside of the GPU’s SRAM. It has to be chopped up and processed by multiple GPUs in parallel.
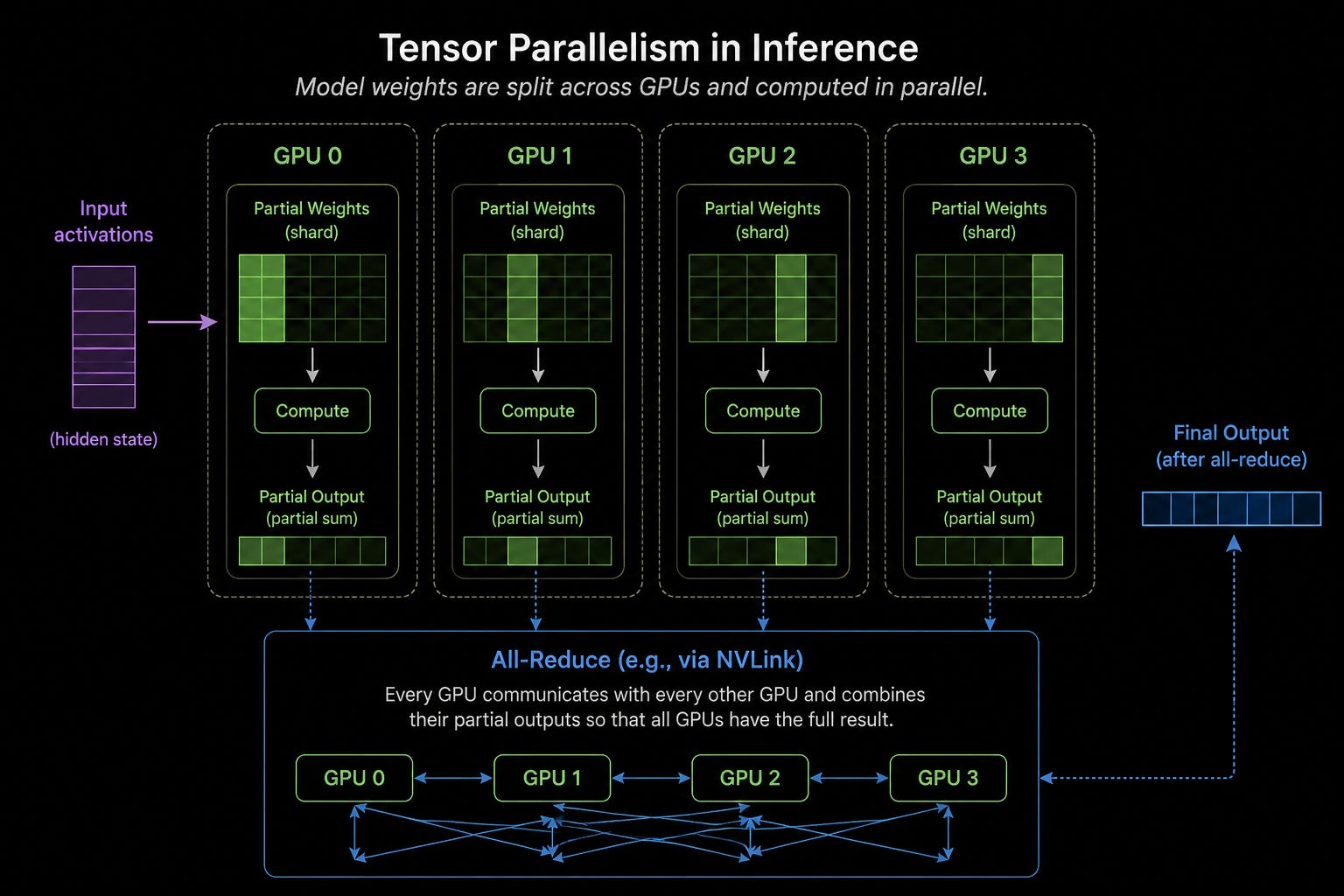
Once the separate GPUs are done, they have to share their answers via an all-reduce, where every GPU has to talk to all others. This generally happens within the same NVLink scale-up domain so we’re talking about microseconds of latency, which doesn’t sound that bad, but there are two things that actually make it pretty problematic for fast inference.
First is that this all reduce must happen for every single token the model generates as decode is sequential.
Secondly, not only does it have to happen for every token, it has to happen for every layer of the model. Transformers are made up of many attention and multi-layer perceptron layers.
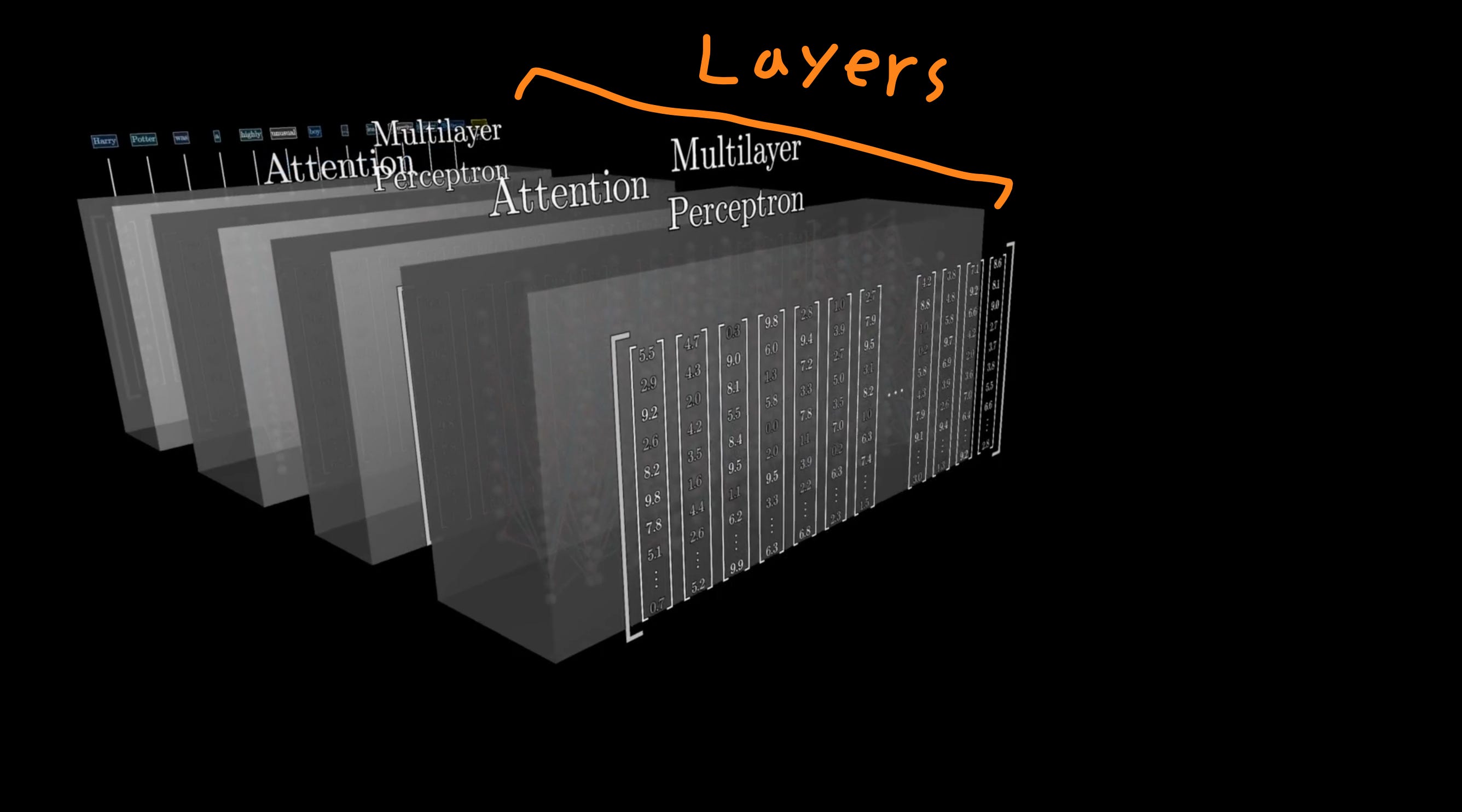
So for a 100-layer model, every token generated requires 100 all-reduce operations across the tensor parallelism group. If you have a lot of tokens, that’s a lot of latency!
There is also a separate latency bottleneck caused by HBM. Each time you generate a token, you have to load the model weights from the HBM to the compute. This is completely separate from the all-reduce and the tensor parallelism approach we just discussed, but is another reason why Cerebras is able to absolutely speedmog Blackwell.
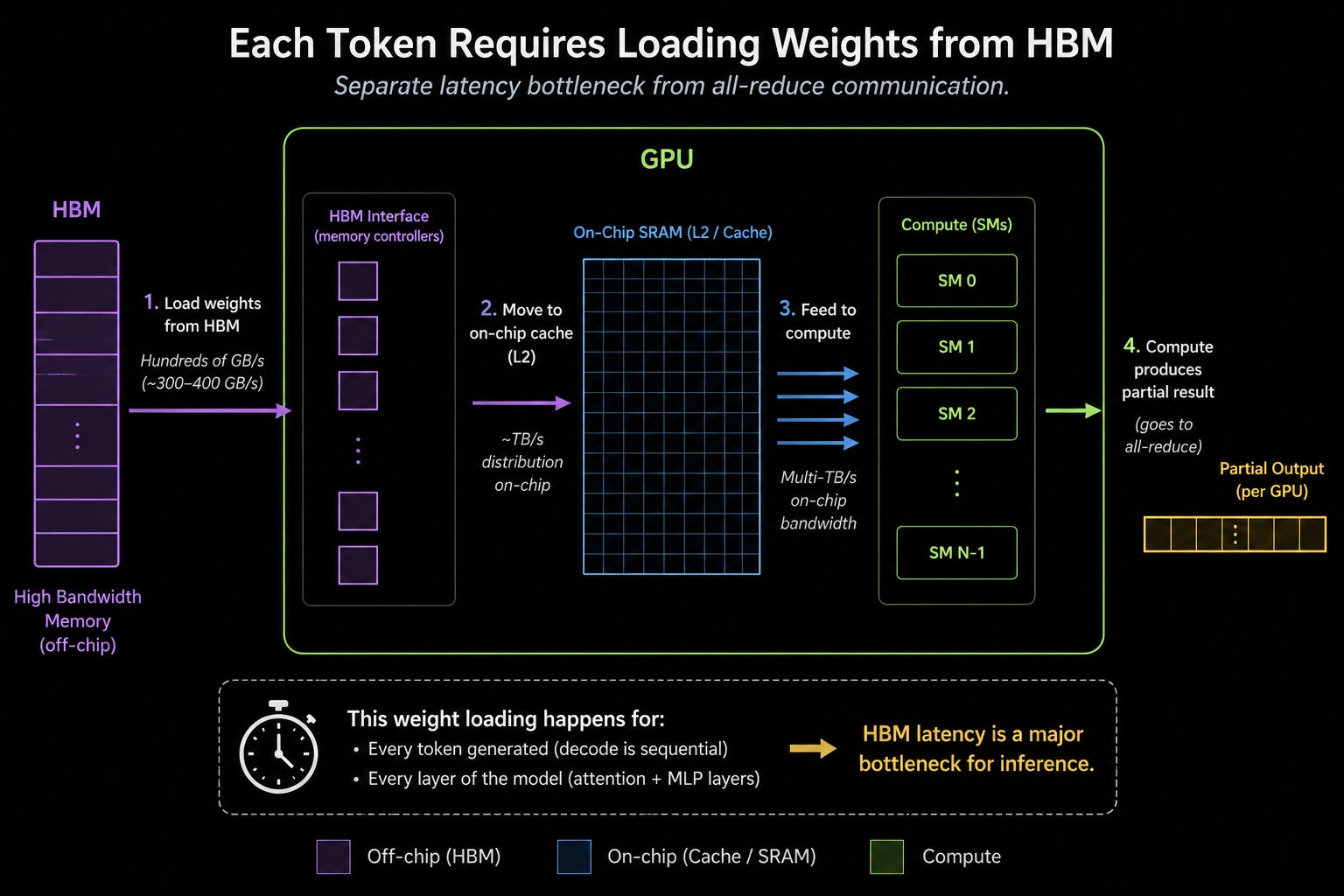
All in all, several microseconds of latency per token results in the general hundreds of tokens per second achieved by regular normal GPUs.
Pipeline Parallelism
Pipeline parallelism is like a pipeline.
Like I said the model is made up of a bunch of layers. Each time you do the math of one layer, you get an activation output, which you pass downstream of the pipeline to the next layer.
Now here’s where Cerebras comes in. Cerebras has a big ahh chip. Whereas GPUs cannot fit entire layers of a model on their SRAM, Cerebras can. Therefore, when Cerebras does matrix math, it does not need to run an all-reduce operation to combine the answers for different slices of the model layers. It also doesn’t need the HBM. All the communication happens on-chip, and on-chip communication is very speedy.
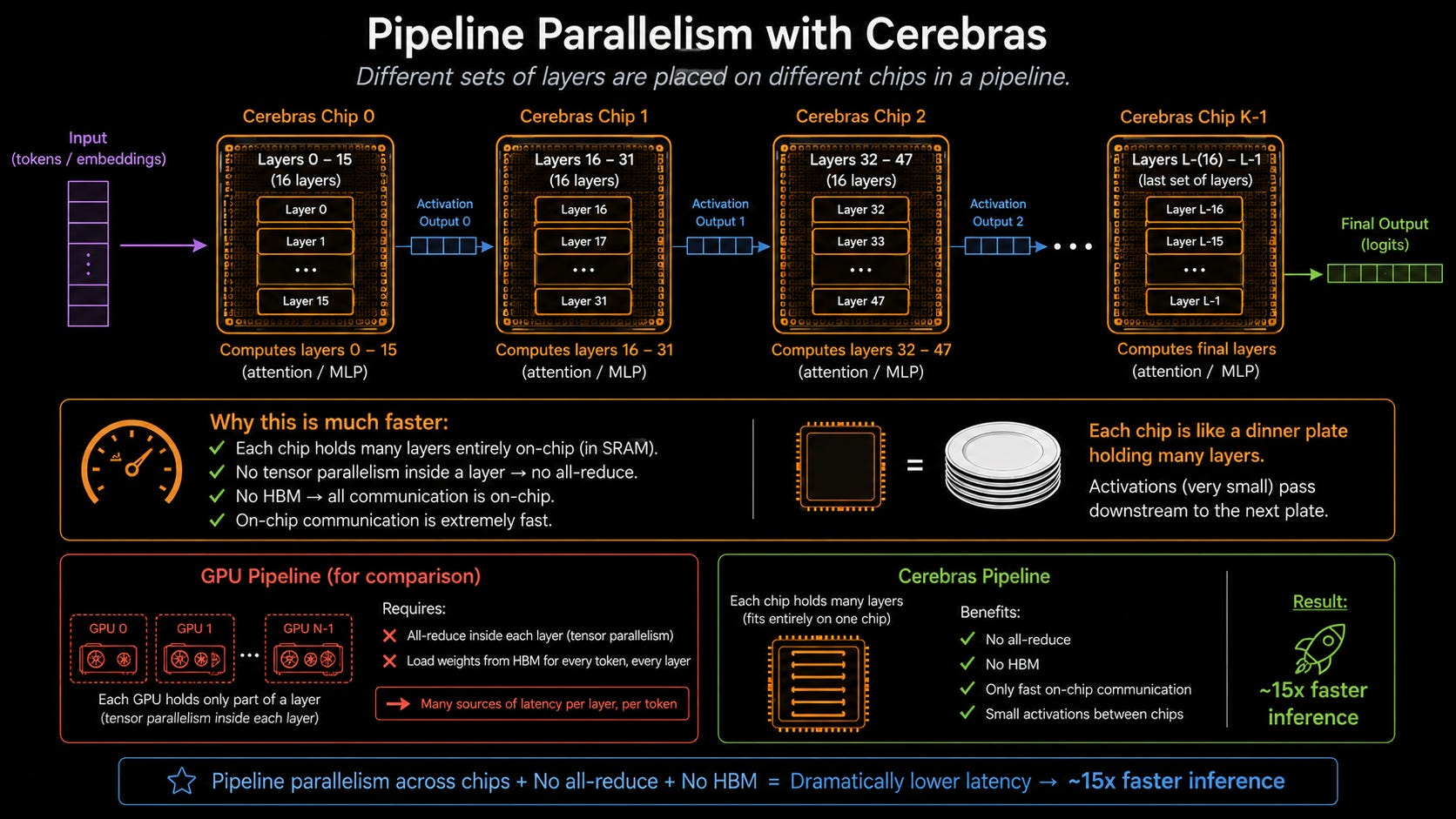
Notice I say model layers and not model. This is important. Cerebras doesn’t put the entire model on one chip. It’s still not big enough to do that. It simply strings a whole bunch of dinner plates together, with each one processing many layers, getting the activation outputs and passing that downstream to the next set of layers. Cerebras has major IO bandwidth bottlenecks (which we’ll talk about later), but that is not an issue here because the activation outputs are very small.
The result? Data literally flows down the wafers like water through a river. Smooth, buttery, and unbothered. 15 times faster inference by cutting out the all-reduce and HBM communication latency.

Memory Constraints
Remember when I told you they have 48 KB of SRAM per compute core, which is 44 GB per dinner plate? Well, turns out this is not nearly enough to do anything useful in the world of frontier models.
To serve a model, you must fit both the weights and the KV cache (context) into the SRAM. 44 GB isn’t even enough for most models’ weights; and the KV cache is way larger too. To fit a classic open source model, like one of the smaller, dumber Llama ones or the more important DeepSeek V4, you will need a single-digit number of dinner plates to hold the weights and a double-digit number of dinner plates to hold the KV cache.
Because each dinner plate has so little memory but yet is so expensive, this makes serving models using Cerebras very, very capital inefficient.
The I/O Bandwidth Problem
Now you might be asking, why don’t we just offload the KV cache to HBM outside of the wafer?
Funny enough, the picture of the chip itself should hand you an obvious clue.
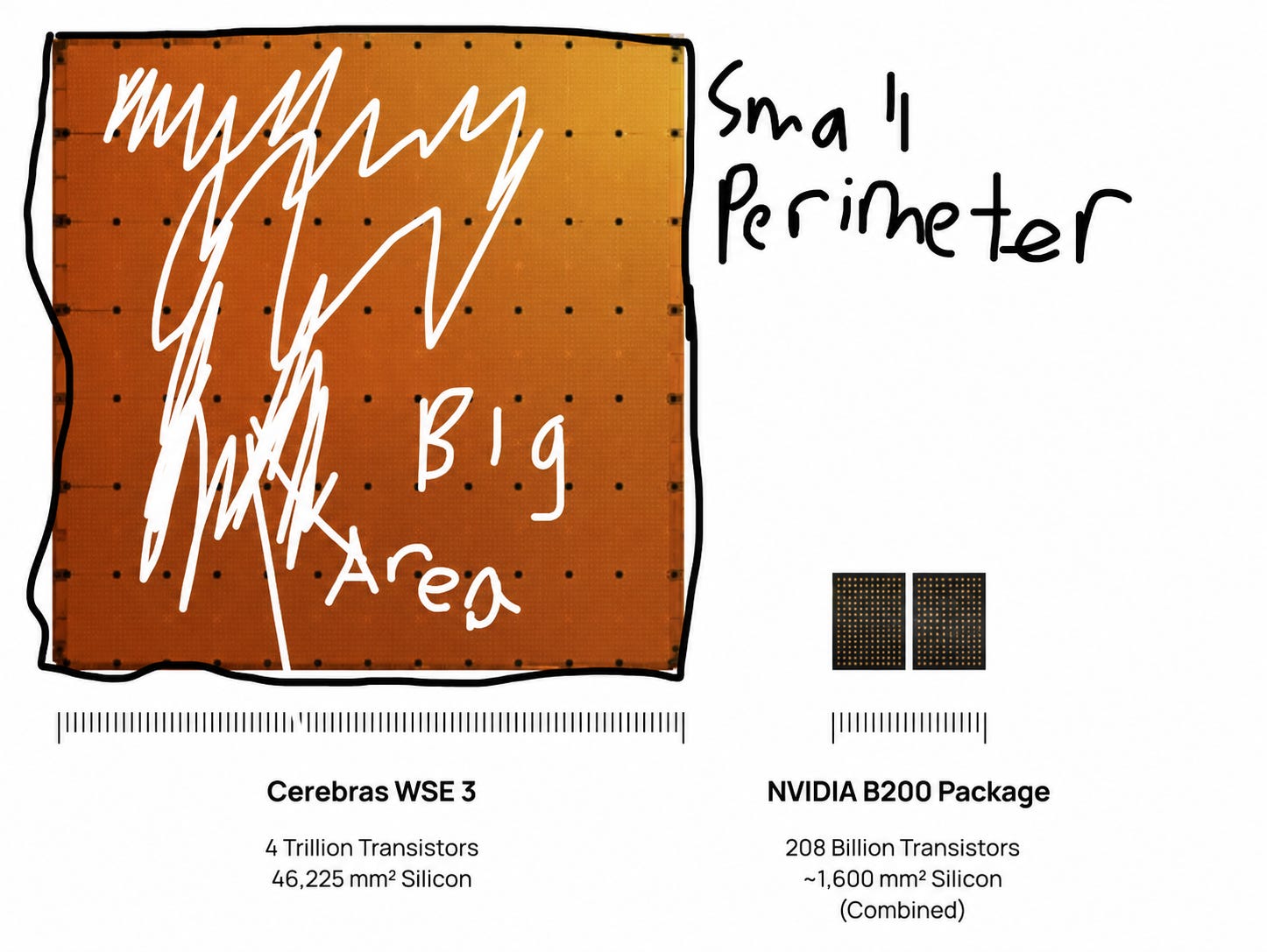
BIG AREA SMALL PERIMETER
The off-chip bandwidth is 1.2 terabits per second, compared to 21 petabits per second for internal bandwidth. That means that data within the chip travels more than ten thousand times faster than data going off the chip.
Beyond that, it also does not compare favorably to GPUs. For the B200 as an example, it has 14.4 terabits per second, which is over 10 times that of the WSE-3. This is like having a massive Olympic-sized swimming pool, but the only physical way to fill it or drain it is by sucking the water through a single, thin plastic drinking straw.

This is also a major reason why their hardware failed in training. Training requires data to be constantly passed from on-WSE to external memory which it absolutely does not have the I/O bandwidth for. This is intuitive, as you can imagine the WSE’s job in training would be to mimic a massive, optically linked GPU cluster while in inference, it only needs to imitate a few servers or a rack.
But the important conclusion here is that there is no escape: both the weights and the KV cache must be held by the on-chip SRAM at all times.
Economic Relevance
What does this all mean?
Well, think about what we’ve covered.
We’ve established that the WSE is a fundamentally different architecture than the GPU. It requires an incredibly complex compiler, redundant communication pathways, and PVT calibration. It is very, very different.
We explored what makes this very different chip better via pipeline parallelism, a feature that allows Cerebras to run inference over 15 times faster than traditional GPUs by avoiding the all-reduce and HBM latency.
We looked at what makes this very different chip worse, namely the suffocating memory constraints and tiny I/O bandwidth.
Notice something here: the advantages are about speed and quality of the experience of the user being served by the chip, while the drawbacks are all measured in number of bits and are about the sheer cost and economic unattractiveness of such quality service.
This leads us to our conclusion. What makes this chip better is that it generates tokens faster, but what makes it worse is that it is far more expensive to generate each token. Cerebras and wafer-scale computing in general is a provider of fast, premium-priced tokens.
The business side of this company is all about exploring whether such speed is worth the extra cost. Are people actually willing to pay for such expensive but fast tokens? Will this type of token take share from the traditional NVIDIA-generated kind? Are there new use cases that require this type of token that we haven’t been able to unlock yet because the hardware didn’t exist, or is the current regime already good enough for all of our uses of AI?
Let’s find out together.
Financials
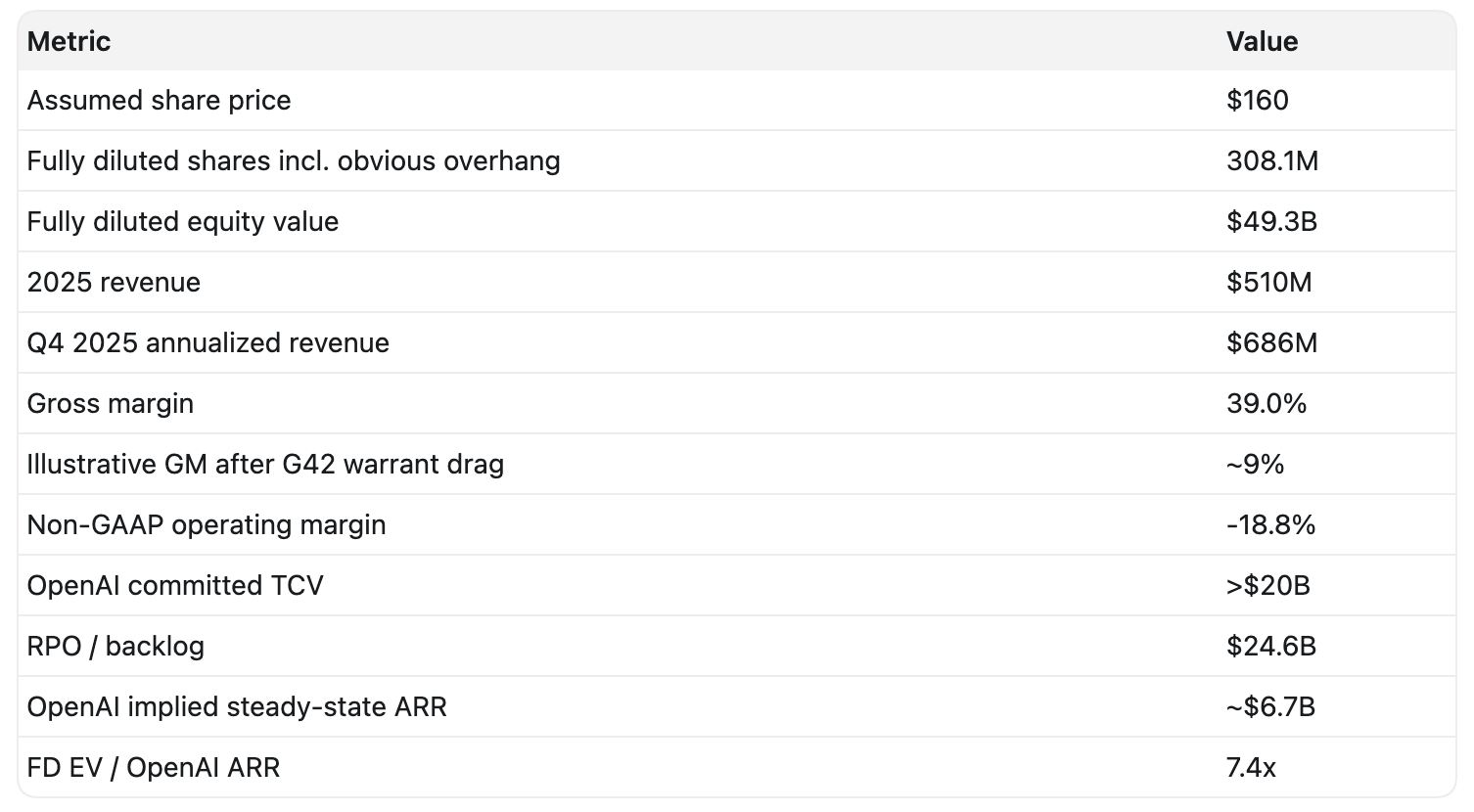
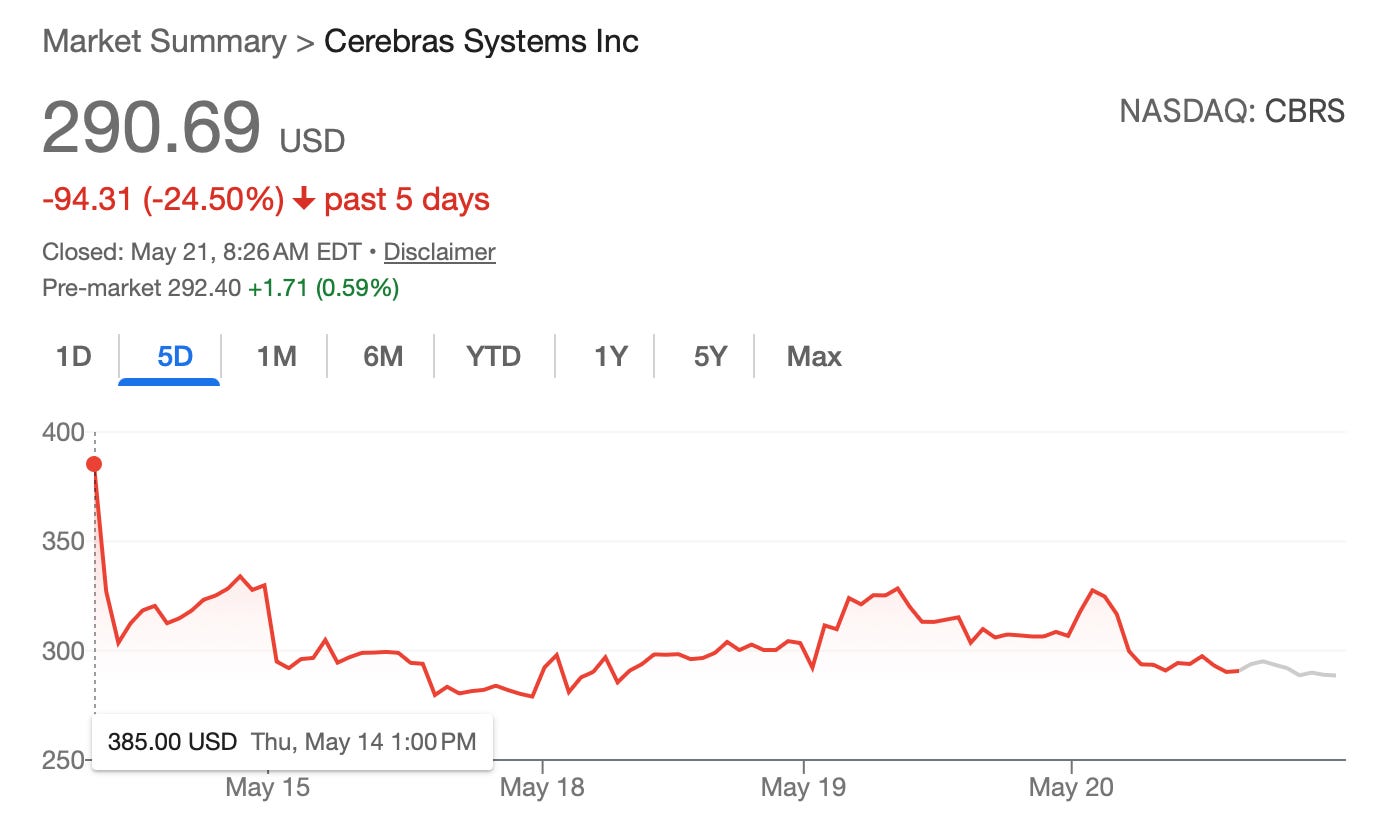
Cerebras IPO was 20 times oversubscribed at the initial $130 share price. People really want to buy this thing. Yesterday, they raised the IPO price to $160. Polymarket still has almost a 100% chance that they will close above a $50 billion market cap (that is for their basic equity value, which is only around 70% of their fully diluted, so it is way higher than what’s shown in the table).
Their 2025 revenue is miniscule and irrelevant at $510m. Currently, they have $24.6b RPO and $20b of contract value from OpenAI, which can be expanded over time, but this implies a $6.7 billion steady-state ARR.
At the assumed IPO price of $160 per share multiplied by the fully diluted share account, the implied revenue multiple to OpenAI’s ARR is 7.4x.
The First Noble Truth of Cerebras
The following is the first Noble Truth of Cerebras.
The financials are useless. Completely utterly useless. Forward estimates are useless. Growth rates are useless. Multiples are useless.
Now, why is that? Let’s think about this from first principles.
How To Think About Cerebras
Cerebras is a canonical example of an unproven technology early in its S-curve with potential for high double-digit to triple-digit growth. This high-level conceptual profile allows us to anchor to two companies that have plenty of coverage on this channel: Lumentum and Bloom Energy.
Lumentum
The 30,000ft intellectual framing of Lumentum is simple: one market (optics) is guaranteed (by the laws of physics) to replace another (copper) to achieve full dominance of a certain use case (AI networking).

Because the transition is inevitable, the leading players in the new market have a massive guaranteed growth runway. This is why optics are so hot.
At the same time, the growth is measured and measurable. It is easy to model. We can confidently predict that Lumentum has 50% year-over-year growth because we can simply use the growth rate of optics as an anchor.
Bloom Energy
Bloom is slightly different. One company provides an objectively superior solution for one single market, which has the potential to fully displace the incumbent.
This is different from Lumentum because the market doesn’t change. Bloom plays in behind-the-meter energy, just like GE Vernova. They are direct competitors. There is no copper equivalent. There is no transition from one market to another.
Because of that, Bloom’s growth can be a little bit more unpredictable and bursty. There is no big Kager number to go off of. It is just a matter of how quickly customers adopt the new solution and how much, or if, the new solution is superior to the old one. However, growth here is still predictable. If the new solution is better, it will still slowly displace the incumbent.
Cerebras
Cerebras is completely different.
From our first article, we ended with the ultimate conclusion that Cerebras is a provider of a fundamentally different product than Nvidia: premium tokens. Premium tokens are way faster but cost way more.
Is Cerebras like Lumentum? No, there is no world in which premium tokens will inevitably displace normal tokens. They are simply two different products each with a different trade-off.
Is Cerebras like Bloom Energy? No. WSE is not a superior way to generate the same end product (electricity for Bloom, regular tokens for NVIDIA).
In both comparisons, Cerebras is actually much worse. It’s not guaranteed to take share from anyone, really. However, there is one critical distinction, and it’s very critical. Very, very critical.
The inference market is the single biggest market in the world.
AI networking and behind-the-meter power are big markets, but they’re not the biggest. Inference is, and the current incumbent is the biggest company in the world. If these premium tokens carve out a large enough slice of this overall pie, Cerebras is a very attractive investment. The only question is, will it carve up a larger left slice? Again, unlike Lumentum, it is not guaranteed to take any share at all.
Now you probably understand why I say that the financials are useless. Single-digit billions of ARR do not matter at all. If you are unprofitable and your market is the biggest market in the world, what matters much more, and really what matters at all, is the slice of the fast inference pie.
No amount of revenue will save Cerebras from offering a fundamentally unwanted solution. No valuation is too high if they serve a sizable fraction of all inference.
Therefore, the point of this article is to simply assess how likely it is the fast inference market ends up being incredibly large.
5.3 Codex Spark
5.3 Codex Spark is the custom-developed model by OpenAI, specifically made for running fast inference on Cerebras hardware. It is currently the only custom design model for Cerebras hardware, so in reality this model is one of, if not THE most important element of any Cerebras investment analysis. But for some reason, it is very under discussed.
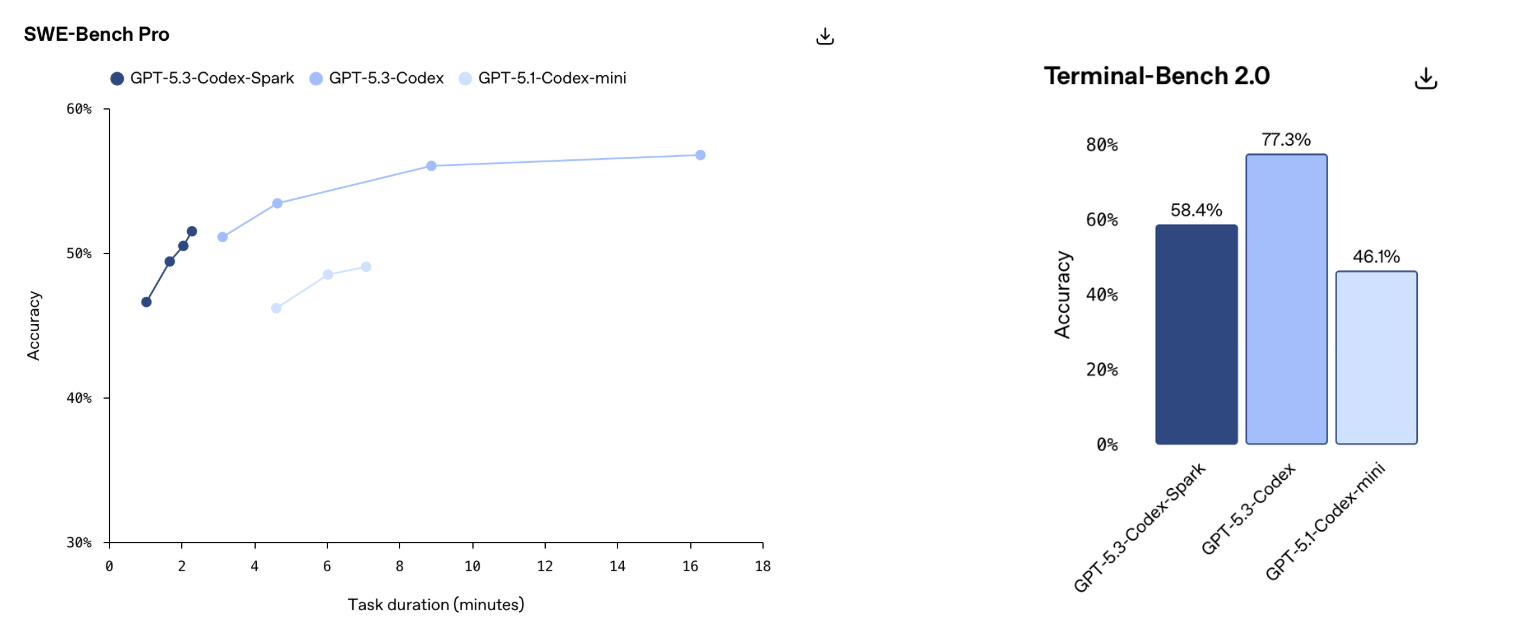
It trades a large chunk of its performance to be smol. It features substantially lower benchmark performance, a context window that is one-eighth of the leading frontier models today, but with inference speeds of over 1,000 tokens per second.
As we established in the last post, in order to run a model of a certain size, a certain number of dinner plates must be strung together. The larger the model weights, the more wafer-scale engines are needed, and the more uneconomical it becomes. Therefore, small models are much more cost-efficient for Cerebras to run.
Now, how good is this model exactly? Here is where I found something funny.
The Cerebras IPO is one of the most hyped events of all time, but the only custom-designed model for its hardware, 5.3 Codex Spark, is one of the most un-hyped and un-loved models out there.
X Sentiment
AI lives on X, so let’s start with the X sentiment. Funny enough, I couldn’t find big accounts that posted about 5.3 codex spark just because of how underdiscussed it was, but there were enough posts for me to come to the conclusion that people generally did not like this model at all.



The main complaint is just the performance. It is a stupid model, to put it simply. Frontier intelligence unsurprisingly requires a certain amount of brute force that small models cannot muster.
My Own Testing: Equity Research
I have a little bit of a bias against benchmarks and testing that people usually do for these models. I don’t care about your score on Humanity’s last exam or whether you can build a snake game in one shot. These are not tasks that I will be doing in real life. This is a point people say a lot, but I think it is underappreciated because they are categorically different from benchmark tasks.
So, to that end, we will be doing two tests that I literally came up with by just asking myself what the next thing I have to do is. Which are equity research and coding.
In a very meta turn of events, I asked both 5.5 and 5.3 Codex Spark to look for pricing and usage data for 5.3 Codex Spark. So using Cerebras to evaluate Cerebras.

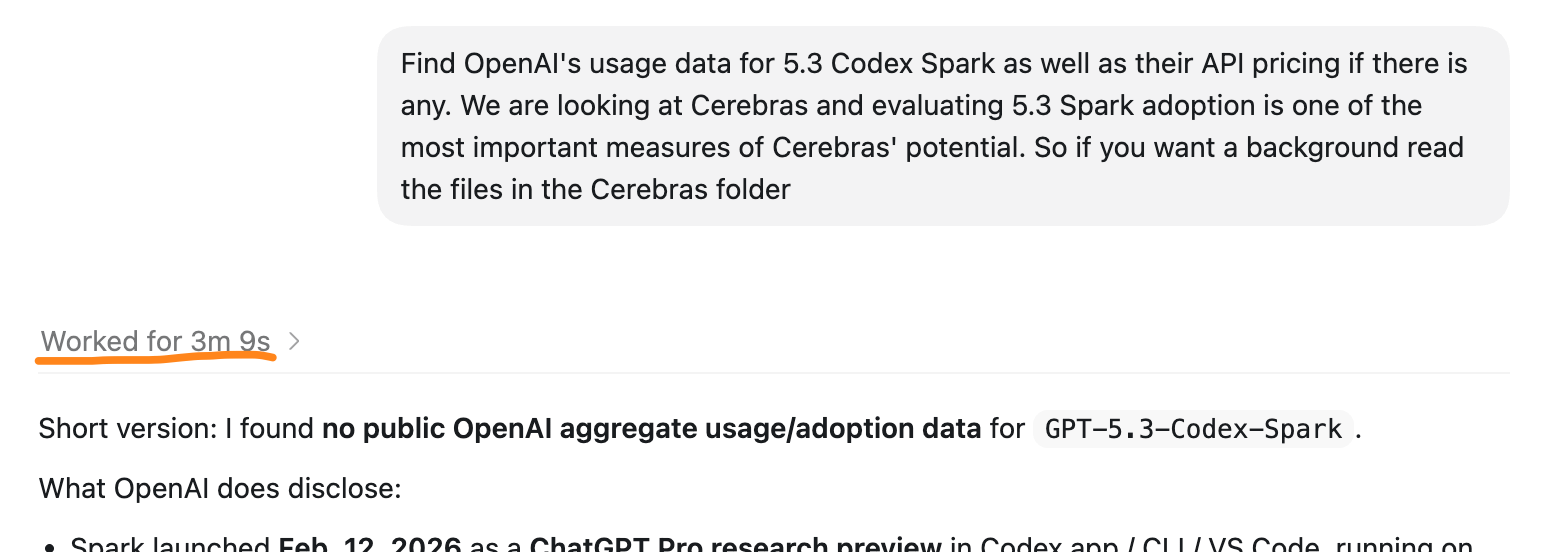
This is mainly a speed test. It is very difficult to gauge quality on research tasks because it is very subjective and could require large sample sizes all evaluated qualitatively before you can get a real sense of the difference. That is why we’re doing coding too.
But for speed, you might notice something interesting. Although Cerebras is supposed to be over ten times faster, 5.3 codex spark took 2 minutes and 19 seconds, while 5.5 took 3 minutes and 9 seconds. This means that 5.5 only took 36% more time rather than 900% more time.
This is because of two reasons. Both of which I observed first hand in my testing and is something us semiconductor people talk about all the time.
A large fraction, or maybe even a majority, of the time spent on doing the task was on web searches, tool calls, and JavaScript executions. Sound familiar? That’s right! CPUs strike again. All those research reports on how a large fraction of the latency in inference is CPU-bound. Well, turns out it isn’t just theory. 5.3 Codex does this really funny thing where it generates tokens in a millisecond, and then you have to wait two or three seconds for the CPU to run the tool call. You all should try it. It feels really weird, but you will immediately understand why CPUs are needed and why having fast inference isn’t all that it’s cracked up to be if you’re only speed boosting half of the workload.
Because the context window is so small, compaction happens very often. Every time the model has to compact its context, more latency is introduced. Even in that short two-minute task, GPT-5.3 Codex Spark had to compact its context, which is why it didn’t finish that far ahead of 5.5, which has a context window of a million tokens. Having a larger context window actually reduces latency by allowing the model to run without compaction for longer.
My Own Testing: Coding
I’m currently developing a full stack terminal for semiconductor investors, which I hope to release by the end of this month. It has a bunch of cool features like:
A Pokédex of every single AI infra company, split up by industry and niche
A map of all HPC co-location sites from the Bitcoin miners
A portfolio lab for backtesting and paper trading
An earnings calendar where you can view upcoming earnings, add events to your calendar, and download transcripts for past events
A Taiwan revenue tracker
A memory price tracker
An API endpoint for AI agents to access the app’s features autonomously
10 different calculators
Therefore, I assigned both models to build my next feature, which is a paper trading feature for the portfolio lab.
This was not a good test for speed because 5.5 ended up pulling up the in-app browser to test as if it were a real user, while 5.3 Spark just shipped it immediately. They made completely different workflow decisions, which means that it cannot be compared apple to apples, unlike for the equity research task. Even then, GPT 5.5 took 16 minutes, while 5.3 codex Spark took 3 minutes, which is only about a 5x difference. That’s still not 10x, even with one model doing way more!
How did they perform? Let’s look at 5.5 first. GPT 5.5 successfully implemented the paper trading feature, and I was able to create my new paper portfolio called Bloomentum.
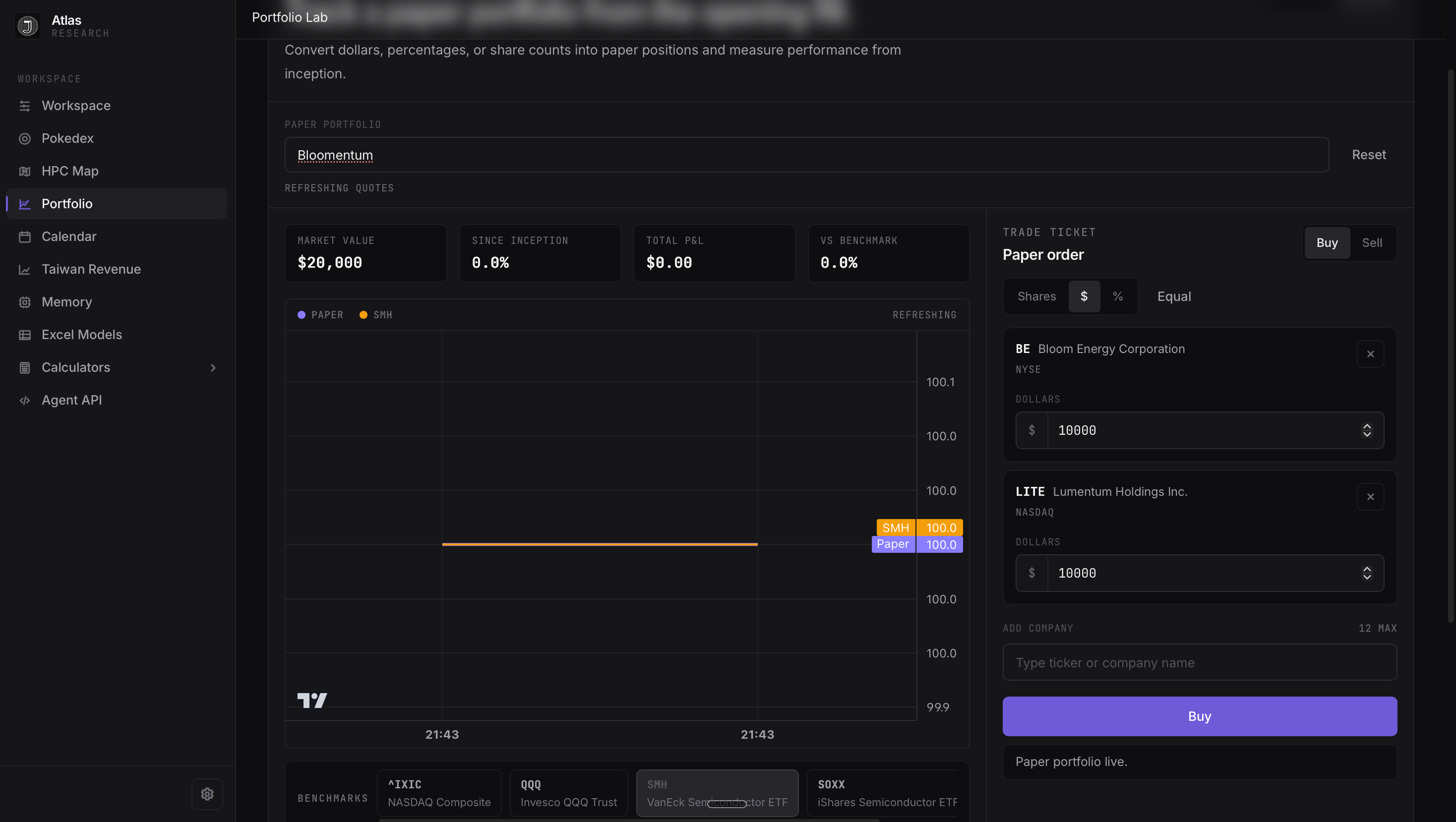
5.3 Codex Spark, on the other hand, had this result.
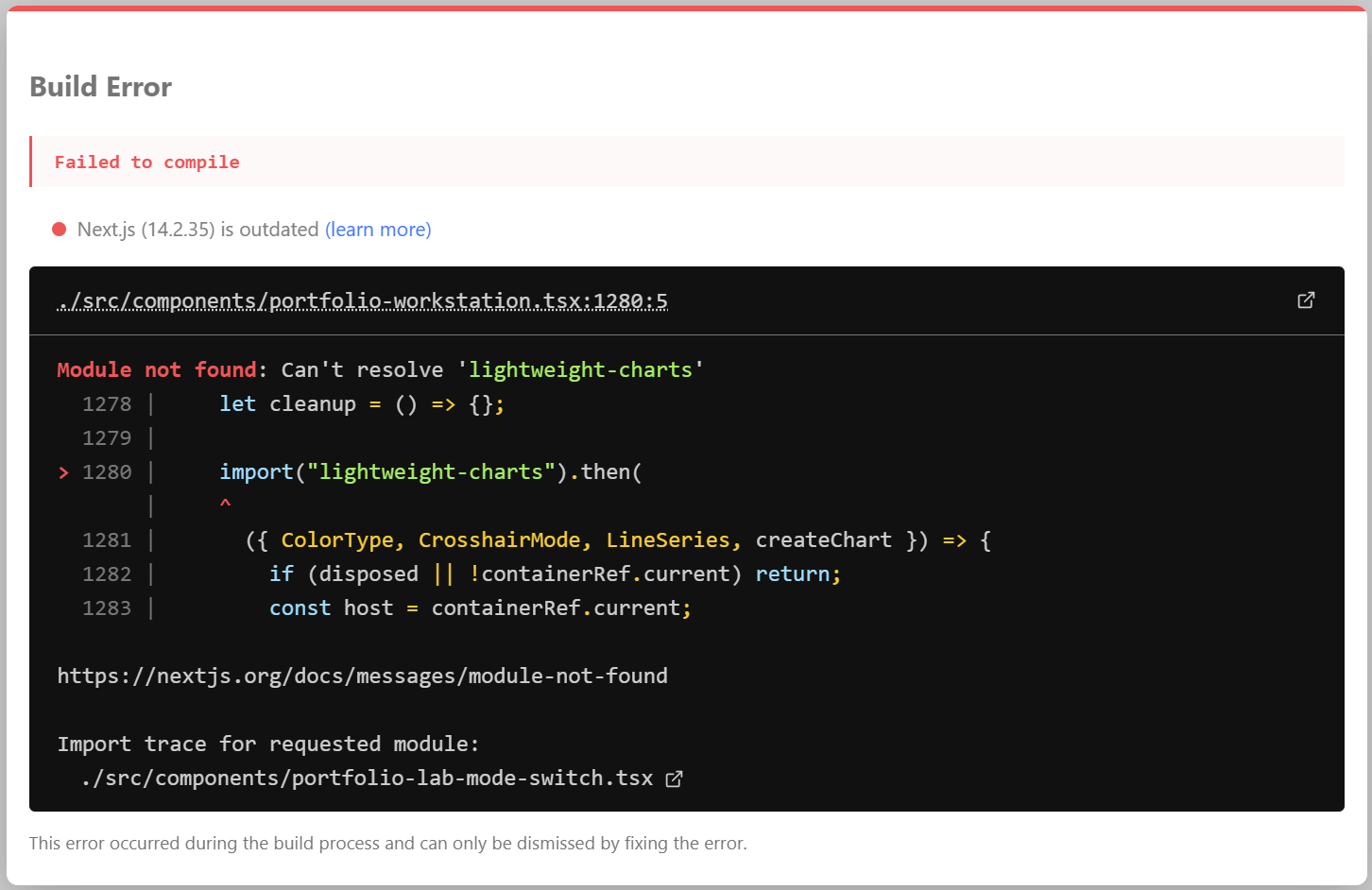
To see the actual finished product that 5.3 Codex Spark can create, I pasted the error back in and allowed it to fix the bug.
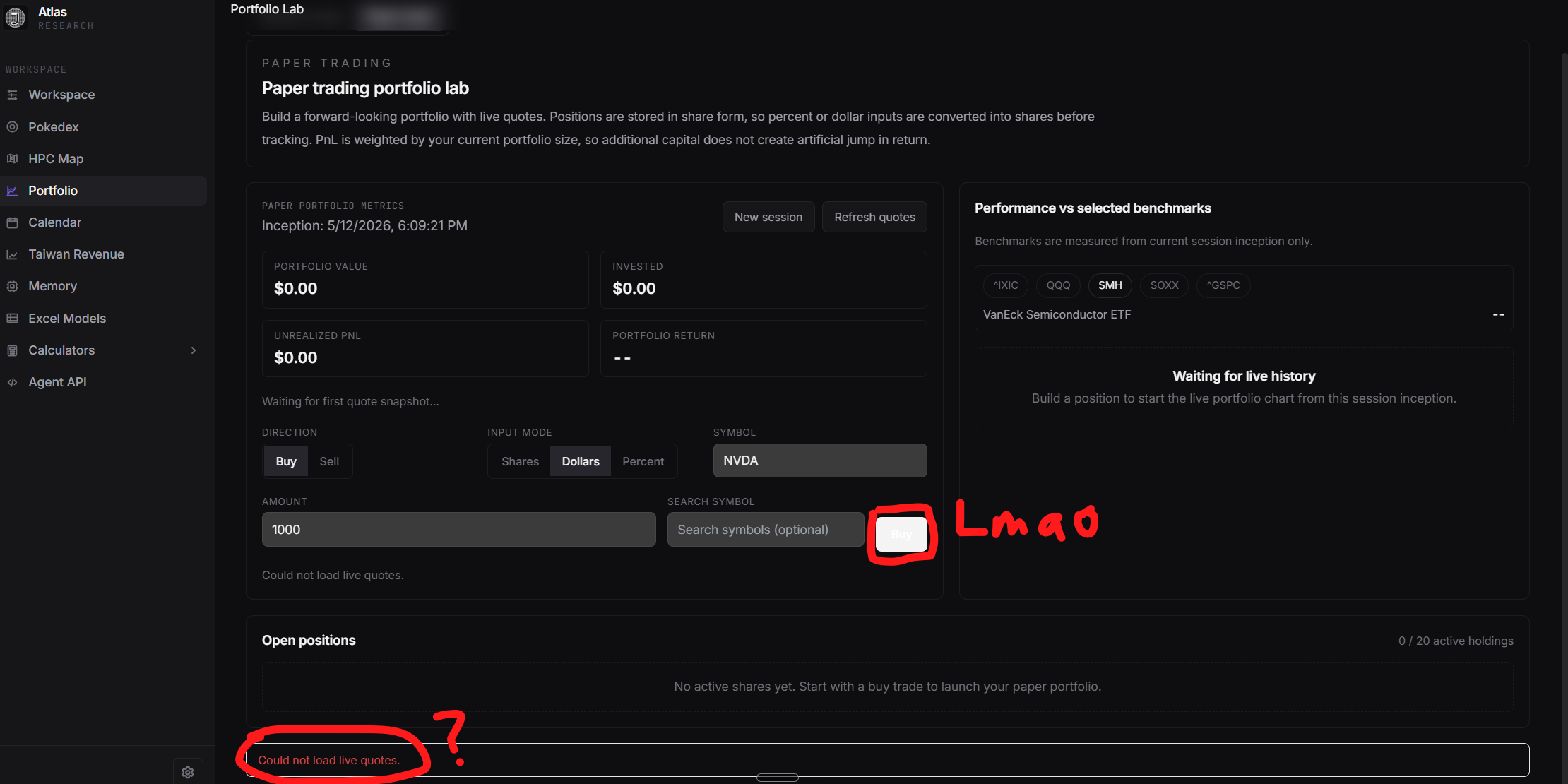
The quality of the work done by 5.3 Codex Spark is far worse. First of all there is another bug: the pricing quotes do not load at all. But if you just look at the UI of this tool, you can already notice the difference. It is very unintuitive and unfriendly to use. It is black and white instead of matching the colors of the app. The buy button isn’t even legible!
Additionally there’s this weird jittery effect where whenever you click a button or type something in, the elements sort of flicker.
Conclusion
Is 5.3 Codex Spark faster? Yes, without a doubt. However, is it 10 times faster like Cerebras claims? Not at all. Real-world workloads are not just pure feed forward. There are tool calls and there are context limitations. Just like doing well on the SAT doesn’t guarantee that you will be successful in a real-life career, running fast inference on a benchmark test in a lab does not guarantee that that same speedup applies in real life.
The performance difference, however, is extremely significant. There is a reason that people gravitate towards frontier-level intelligence even when cheaper open source alternatives exist. OpenAI and Anthropic’s combined ARR is not $80 billion for no reason. More intelligent models do things better. Not only do they do things better, they usually find ways to do them more efficiently, using less tokens in the process, and do it quicker as well. Not because of the sheer inference speed, but because of their superior reasoning abilities. The time it takes to correct bugs and failures, like the one seen in our test, will most likely overwhelm any gains from faster inference as the magnitude of the speed up in real life work just isn’t big enough.
And finally, one overlooked signal is the existence of 5.3 codex spark itself. OpenAI does not have an ultra-fast Cerebras option for GPT 5.5. They purposefully created a smaller weaker model optimized to run on this hardware. That’s actually pretty telling because it was a deliberate choice. They definitely thought about serving the frontier model on Cerebras first and then through testing and deliberation decided against it as it was either impossible or uneconomical.
Bull Case
Let’s be honest, these 5.3 codex spark tests were pretty bearish, so what’s the actual bull case? Well, I think I have a few.
The Undiscovered TAM
The undiscovered TAM argument simply posits that nobody really knows what fast inference could be used for, so the addressable market is completely undiscovered. Because nobody knows about these use cases, there is no market recognition of it, and because there’s no market recognition of it, it must be underpriced.
Here are three potential use cases that I can think of.
Fast Fundamental Investing
I’ve tried once or twice to trade earnings calls and catalysts and have failed every time. I come in with sheer, utter confidence in my fundamental understanding of the company and then get immediately humbled as my thinking speed is way too slow to process the information that was just presented to me and be able to connect that to what happens to the fundamentals of the company.
As you might imagine, this could be something that Cerebras is very good at. Imagine you’re a hedge fund and you have a lot of contacts in a company and a model already built. All you have to do is just give all of that to an LLM and tell it to watch out for catalysts. Once the event hits or the earnings call starts, the model is able to immediately run that inference and tweak the model and come to a conclusion. Having this fundamental-based conclusion just seconds or minutes before everyone else means that you can catch a 10 or 20% move while the rest of the market is still racking their brain around what just happened.
Embodied/Humanlike AI
What if I want an AI in my Zoom call? What if I want to talk to a model and have it interrupt me like my friends do? There is a level of speed required in humanlike back-and-forth conversation to enable idea exchange at a cadence that humans are familiar with.
Think about the way you talk to an AI right now. It is essentially long monologue after long monologue. This is due to the inference speed limitation. You may be able to imagine the plethora of use cases that can be unlocked with this constraint gone.
Robotics is another interesting application here. Imagine if humanoid robots can talk exactly like humans do. This would be an insanely large addressable market that includes all service industries like dining, hospitality, and front desk work.
Real-Time Human Augmentation
Finally, you have real-time human augmentation, which is essentially giving humans an earpiece that can allow an LLM to help that person in real time. Think about high-stakes meetings, live negotiations, that sort of thing.
The Low Hanging Fruit
The second category is low-hanging fruit. Low-hanging fruit being architectural innovations that Cerebras can easily make, which would be a step function change in their unit economics. Because their architecture is so much less mature than traditional GPUs, it is very unoptimized and therefore can be optimized.
FP8 & FP4 Support
The first thing that they can do is to enable FP8 and FP4 support. It is quite puzzling to me why they don’t do this already. They only currently support FP16, which is like having very limited storage on your phone, but the software only permits you to store photos and videos in 4K HD.
I think it’s likely because if they enabled this support, they would have to redesign their cores. Since their original design was meant for the training market, it was never optimized in this way. Anyways, there are rumors that this should be coming to the WSE-4, and that would unlock an easy 2x improvement in memory capacity.
Hybrid Bonding
The second thing they can do is more speculative. What if they hybrid bond an entire SRAM wafer on top of their WSE? It would be quite difficult, as it involves solving a ton of engineering problems and foundry shenanigans.

If they can do this, they scale their memory by an order of magnitude. Honestly, it would make Cerebras a completely different story.
But again, it is very speculative, and there’s no indication that they’re pursuing this.
The Non-Nvidia Ecosystem
Because Nvidia acquired Grok, they are the only major accelerated computing provider to have a fast inference solution. AMD and the hyperscalers are left without one. As you can see this argument is quite simple: the only way for them to compete effectively with Nvidia’s Grok LPU racks is to partner with Cerebras. All of Cerebras’s competitors are far behind and do not have comparable commercial traction, whether it’s MatX, SambaNova, or D-Matrix. Cerebras would be the only choice.
Conclusion
Because there are fixed, unchanging real-world constraints on total latency of agentic inference, there comes a phenomenon of diminishing returns on speeding up the feed forward itself, as there is no amount of pure transformer feed forward shenanigans that you can do that will make your CPUs do web searches, run JavaScript, and call tools faster. I believe Cerebras is well past that point. In my experience, GPT 5.5 low fast latency is already far more dependent on CPUs than the GPU.
The only model that is custom made for Cerebras is a subpar performer and has very little commercial traction. This makes me believe that the technical trade-off that they made and their “premium token” value proposition that we discussed in our last article does not currently have a market fit.
Therefore, I stayed out of the IPO.
However, I will still be watching this company very closely because of the bull cases. None of them are currently unfolding today, but if they do, this entire story can flip on its head. The thing is, I am not going to speculate on them. I want to see them happen before I get in. If I miss the first 100% to guarantee that the thesis actually exists, that’s okay. Just look at the Bloom Energy or Lumentum charts. Anybody who missed the first 100% probably aren’t complaining about it.
Great article. The first thing I learned when I started to study AI GPUs is that the bottleneck is memory, and you have to stack multiple NVidia GPUs together to pile up 2.05T of RAM to load a 1T parameter model like Kimi K2.5 without quantisation. And now Cerebras is betting their whole business on the "10x-faster but 10x-smaller" mode. Cerebras isn't even compatible to HBM, apparently. Let's see.
Love the article. The interesting Cerebras question is whether they can create a new premium inference category where latency is the product.
Most inference probably does not need this. A coding agent, research agent, or enterprise workflow can generate tokens faster and still feel slow because the bottleneck is somewhere else: tool calls, retrieval, verification, approvals, retries, crappy SaaS APIs. In those cases, faster decode is nice but not necessarily monetizable.